Journeys of a not so young anymore Software Engineer
Software Engineering, Humans, Ruby, Elixir, the web
The great Rubykon Benchmark 2020: CRuby vs JRuby vs TruffleRuby
It has been far too long, more than 3.5 years since the last edition of this benchmark. Well what to say? I almost had a new edition ready a year ago and then the job hunt got too intense and now the heat wave in Berlin delayed me. You don’t want your computer running at max capacity for an extended period, trust me.
Well, you aren’t here to hear about why there hasn’t been a new edition in so long, you’re here to read about the new edition! Most likely you’re here to look at graphs and see what’s the fastest ruby implementation out there. And I swear we’ll get to it but there’s some context to establish first. Of course, feel free to skip ahead if you just want the numbers.
Well, let’s do this!
What are we benchmarking?
We’re benchmarking Rubykon again, a Go AI written in Ruby using Monte Carlo Tree Search. It’s a fun project I wrote a couple of years back. Basically it does random playouts of Go games and sees what moves lead to a winning game building a tree with different game states and their win percentages to select the best move.
Why is this a good problem to benchmark? Performance matters. The more playouts we can do the better our AI plays because we have more data for our decisions. The benchmark we’re running starts its search from an empty 19×19 board (biggest “normal” board) and does 1000 full random playouts from there. We’ll measure how long that takes/how often we could do that in a minute. This also isn’t a micro benchmark, while remaining reasonable in size it looks at lots of different methods and access patterns.
Why is this a bad problem to benchmark? Most Ruby devs are probably interested in some kind of web application performance. This does no IO (which keeps the focus on ruby code execution, which is also good) and mainly deals with arrays. While we deal with collections all the time, rubykon also accesses a lot of array indexes all over, which isn’t really that common. It also barely deals with strings. Moreover, it does a whole lot of (pseudo-)random number generation which definitely isn’t a common occurrence. It also runs a relatively tight hot loop of “generate random valid move, play it, repeat until game over”, which should be friendly to JIT approaches.
What I want to say, this is an interesting problem to benchmark but it’s probably not representative of web application performance of the different ruby implementations. It is still a good indicator of where different ruby implementations rank performance wise.
It’s also important to note that this benchmark is single threaded – while it is a problem suited for parallelization I haven’t done so yet. Plus, single threaded applications are still typical for Ruby (due to the global interpreter lock in CRuby).
We’re also mainly interested in “warm” application performance i.e. giving them a bit of time to warm up and look at their peak performance. We’ll also look at the warmup times in a separate section though.
The competitors
Our competitors are ruby variants I could easily install on my machine and was interested in which brings us to:
- CRuby 2.4.10
- CRuby 2.5.8
- CRuby 2.6.6
- CRuby 2.7.1
- CRuby 2.8.0-dev (b4b702dd4f from 2020-08-07) (this might end up being called Ruby 3 not 2.8)
- truffleruby-1.0.0-rc16
- truffleruby-20.1.0
- jruby-9.1.17.0
- jruby-9.2.11.1
All of those versions were current as of early August 2020. As usual doing all the benchmarking, graphing and writing has taken me some time so that truffleruby released a new version in the mean time, result shouldn’t differ much though.
CRuby (yes I still insist on calling it that vs. MRI) is mainly our base line as it’s the standard ruby interpreter. Versions that are capable of JITing (2.6+) will also be run with the –jit flag separately to show improvement (also referred to as MJIT).
TruffleRuby was our winner the last 2 times around. We’re running 20.1 and 1.0-rc16 (please don’t ask me why this specific version, it was in the matrix from when I originally redid this benchmarks a year ago). We’re also going to run both native and JVM mode for 20.1.
JRuby will be run “normally”, and with invokedynamic + server flag (denoted by “+ID”). We’re also gonna take a look at JDK 8 and JDK 14. For JDK 14 we’re also going to run it with a non default GC algorithm, falling back to the one used in JDK 8 as the new default is slower for this benchmark. Originally I also wanted to run with lots of different JVMs but as it stands I already recorded almost 40 different runs in total and the JVMs I tried didn’t show great differences so we’ll stick with the top performer of those I tried which is AdoptOpenJDK.
You can check all flags passed etc. in the benchmark script.
The Execution Environment
This is still running on the same Desktop PC that I did the first version of these benchmarks with – almost 5 years ago. In the meantime it was hit by a lot of those lovely intel security vulnerabilities though. It’s by no means a top machine any more.
The machine has 16 GB of RAM, runs Linux Mint 19.3 (based on Ubuntu 18.04 LTS) and most importantly an i7-4790 (3.6 GHz, 4 GHz boost) (which is more than 6 years old now).
| tobi@speedy:~$ uname -a | |
| Linux speedy 5.4.0-42-generic #46~18.04.1-Ubuntu SMP Fri Jul 10 07:21:24 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux | |
| tobi@speedy:~$ lscpu | |
| Architecture: x86_64 | |
| CPU op-mode(s): 32-bit, 64-bit | |
| Byte Order: Little Endian | |
| CPU(s): 8 | |
| On-line CPU(s) list: 0-7 | |
| Thread(s) per core: 2 | |
| Core(s) per socket: 4 | |
| Socket(s): 1 | |
| NUMA node(s): 1 | |
| Vendor ID: GenuineIntel | |
| CPU family: 6 | |
| Model: 60 | |
| Model name: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz | |
| Stepping: 3 | |
| CPU MHz: 3568.176 | |
| CPU max MHz: 4000,0000 | |
| CPU min MHz: 800,0000 | |
| BogoMIPS: 7200.47 | |
| Virtualization: VT-x | |
| L1d cache: 32K | |
| L1i cache: 32K | |
| L2 cache: 256K | |
| L3 cache: 8192K | |
| NUMA node0 CPU(s): 0-7 | |
| Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt dtherm ida arat pln pts md_clear flush_l1d |
All background applications were closed and while the benchmarks were running no GUI was active. They were run on hot Berlin evenings 😉
If you want to run these benchmarks yourself the rubykon repo has the instructions, with most of it being automated.
Timing wise I chose 5 minutes of warmup and 2 minutes of run time measurements. The (enormous) warmup time was mostly driven by behaviour observed in TruffleRuby where sometimes it would deoptimize even after a long warmup. So, I wanted to make sure everyone had all the time they needed to reach good “warm” performance.
Run Time Results
One more thing before we get to it: JRuby here ran on AdoptOpenJDK 8. Differences to AdoptOpenJDK 14 (and other JVMs) aren’t too big and would just clutter the graphs. We’ll take a brief look at them later.
If you want to take a look at all the data I gathered you can access the spreadsheet.
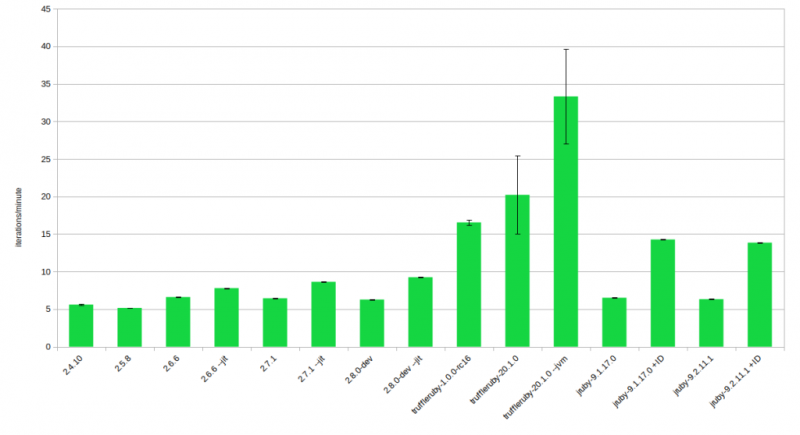
Overall this looks more or less like the graphs from the last years:
- CRuby is the baseline performance without any major jumps
- JRuby with invokedynamic (+ID) gets a bit more than 2x the baseline performance of CRuby, invokedynamic itself makes it a lot faster (2x+)
- TruffleRuby runs away with the win
What’s new though is the inclusion of the JIT option for CRuby which performs quite impressively and is only getting better. An 18% improvement on 2.6 goes up to 34% on 2.7 and tops out at 47% for 2.8 dev when looking at the JIT vs. non JIT run times of the same Ruby version. Looking at CRuby it’s also interesting that this time around “newer” CRuby performance is largely on par with not JITed JRuby performance.
The other thing that sticks out quite hugely are those big error bars on TruffleRuby 20. This is caused by some deoptimizations even after the long warmup. Portrayed here is a run where they weren’t as bad, even if they are worse performance was still top notch at 27 i/min overall though. It’s most likely a bug that these deoptimizations happen, you can check the corresponding issue. In the past the TruffleRuby always found a way to fix issues like this. So, the theoretical performance is a bit higher.
Another thing I like to look at is the relative speedup chart:
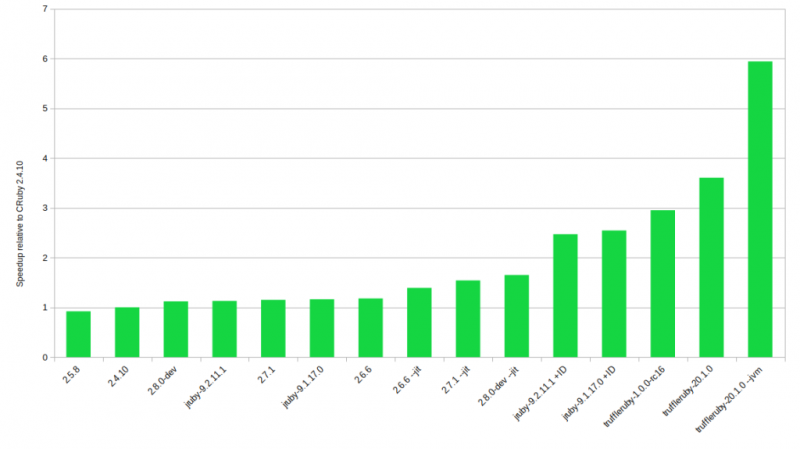
CRuby 2.4.10 was chosen as the “baseline” for this relative speedup chart mostly as a homage to Ruby 3×3 in which the goal was for Ruby 3 to be 3 times faster than Ruby 2.0. I can’t get Ruby < 2.4 to compile on my system easily any more and hence they are sadly missing here.
I’m pretty impressed with the JIT in Ruby 2.8: a speedup of over 60% is not to be scoffed at! So, as pointed out in the results above, I have ever rising hopes for it! JRuby (with invokedynamic) sits nice and comfortably at ~2.5x speedup which is a bit down from its 3x speedup in the older benchmarks. This might also be to the improved baseline of CRuby 2.4.10 versus the old CRuby 2.0 (check the old blog post for some numbers from then, not directly comparable though). TruffleRuby sits at the top thanks to the –jvm version with almost a 6x improvement. Perhaps more impressively it’s still 2.3 times faster than the fastest non TruffleRuby implementation. The difference between “native” and –jvm for TruffleRuby is also astounding and important to keep in mind should you do your own benchmarks.
What’s a bit baffling is that the performance trend for CRuby isn’t “always getting better” like I’m used to. The differences are rather small but looking at the small standard deviation (at most less than 1%) I’m rather sure of them. 2.5 is slower than 2.4, and 2.6 is faster than both 2.7 and 2.8.-dev. However, the “proper” order is established again when enabling the JIT.
If you’re rather interested in the data table you can still check out the spreadsheet for the full data, but here’s some of it inline:
| Ruby | i/min | avg (s) | stddev % | relative speedup |
| 2.4.10 | 5.61 | 10.69 | 0.86 | 1 |
| 2.5.8 | 5.16 | 11.63 | 0.27 | 0.919786096256684 |
| 2.6.6 | 6.61 | 9.08 | 0.42 | 1.17825311942959 |
| 2.6.6 –jit | 7.8 | 7.69 | 0.59 | 1.3903743315508 |
| 2.7.1 | 6.45 | 9.3 | 0.25 | 1.14973262032086 |
| 2.7.1 –jit | 8.64 | 6.95 | 0.29 | 1.54010695187166 |
| 2.8.0-dev | 6.28 | 9.56 | 0.32 | 1.11942959001783 |
| 2.8.0-dev –jit | 9.25 | 6.48 | 0.29 | 1.64884135472371 |
| truffleruby-1.0.0-rc16 | 16.55 | 3.63 | 2.19 | 2.95008912655971 |
| truffleruby-20.1.0 | 20.22 | 2.97 | 25.82 | 3.60427807486631 |
| truffleruby-20.1.0 –jvm | 33.32 | 1.8 | 19.01 | 5.93939393939394 |
| jruby-9.1.17.0 | 6.52 | 9.21 | 0.63 | 1.16221033868093 |
| jruby-9.1.17.0 +ID | 14.27 | 4.2 | 0.29 | 2.54367201426025 |
| jruby-9.2.11.1 | 6.33 | 9.49 | 0.54 | 1.1283422459893 |
| jruby-9.2.11.1 +ID | 13.85 | 4.33 | 0.44 | 2.46880570409982 |
Warmup
Seems the JITing approaches are winning throughout, however such performance isn’t free. Conceptually, a JIT looks at what parts of your code are run often and then tries to further optimize (and often specialize) these parts of the code. This makes it a whole lot faster, this process takes time and work though.
The benchmarking numbers presented above completely ignore the startup and warmup time. The common argument for this is that in long lived applications (like most web applications) we spend the majority of time in the warmed up/hot state. It’s different when talking about scripts we run as a one off. I visualized and described the different times to measure way more in another post.
Anyhow, lets get a better feeling for those warmup times, shall we? One of my favourite methods for doing so is graphing the first couple of run times as recorded (those are all during the warmup phase):

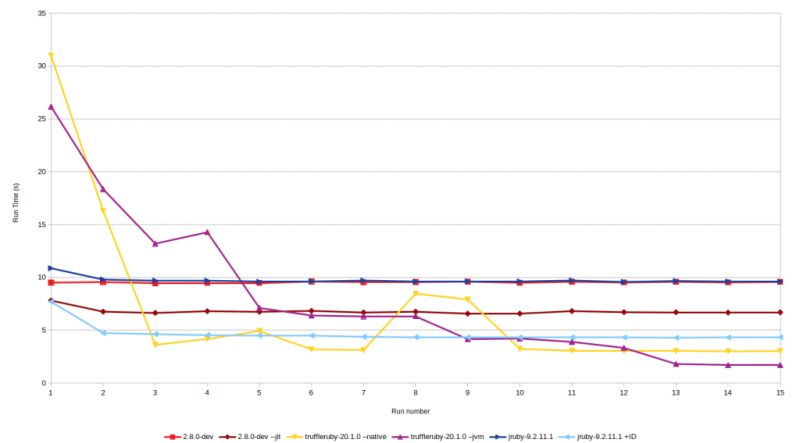
CRuby itself (without –jit) performs at a steady space, this is expected as no further optimizations are done and there’s also no cache or anything involved. Your first run is pretty much gonna be as fast as your last run. It’s impressive to see though that the –jit option is faster already in the first iteration and still getting better. What you can’t see in the graph, as it doesn’t contain enough run times and the difference is very small, is that the CRuby –jit option only reaches its peak performance around iteration 19 (going from ~6.7s to ~6.5s) which is quite surprising looking at how steady it seems before that.
TruffleRuby behaves in line with previous results. It has by far the longest warmup time, especially the JVM configuration which is in line with their presented pros and cons. The –jvm runtime configuration only becomes the fastest implementation by iteration 13! Then it’s faster by quite a bit though. It’s also noteworthy that for neither native nor JVM the time declines steadily. Sometimes subsequent iterations are slower which is likely due to the JIT trying hard to optimize something or having to deoptimize something. The random nature of Rubykon might play into this, as we might be hitting edge cases only at iteration 8 or so. While especially the first run time can be quite surprising, it’s noteworthy that during my years of doing these benchmarks I’ve seen TruffleRuby steadily improve its warmup time. As a datapoint, TruffleRuby 1.0.0-rc16 had its first 2 run times at 52 seconds and 25 seconds.
JRuby is very close to peak performance after one iteration already. Peak performance with invokedynamic is hit around iteration 7. It’s noteworthy that with invokedynamic even the first iteration is faster than CRuby “normal” and on par with the CRuby JIT implementation but in subsequent iterations gets much faster than them. The non invokedynamic version is very close to normal CRuby 2.8.0-dev performance almost the entire time, except for being slower in the first iteration.
For context it’s important to point out though that Rubykon is a relatively small application. Including the benchmarking library it’s not even 1200 lines of code long. It uses no external gems, it doesn’t even access the standard library. So all of the code is in these 1200 lines + the core Ruby classes (Array etc.) which is a far cry from a full blown Rails application. More code means more things to optimize and hence should lead to much longer warmup times than presented here.
JRuby/JVM musings
It might appear unfair that the results up there were run only with JDK 8. I can assure you, in my testing it sadly isn’t. I had hoped for some big performance jumps with the new JDK versions but I found no such thing. Indeed, it features the fastest version but only by a rather slim margin. It also requires switching up the GC algorithm as the new default performs worse at least for this benchmark.

Performance is largely the same. JDK 14 is a bit faster when using both invokedynamic and falling back to the old garbage collector (+ParallelGC). Otherwise performance is worse. You can find out more in this issue. It’s curios though that JRuby 9.1 seems mostly faster than 9.2.
I got also quite excited at first looking at all the different new JVMs and thought I’d benchmark against them all, but it quickly became apparent that this was a typical case of “matrix explosion” and I really wanted for you all to also see these results unlike last year 😅 I gathered data for GraalVM and Java Standard Edition Reference Implementation in addition to AdoptOpenJDK but performance was largely the same and best at AdoptOpenJDK on my system for this benchmark. Again, these are in the spreadsheet.
I did one more try with OpenJ9 as it sounded promising. The results were so bad I didn’t even put them into the spreadsheet (~4 i/min without invokedynamic, ~1.5 i/min with invokedynamic). I can only imagine that either I’m missing a magic switch, OpenJ9 wasn’t built with a use case such as JRuby in mind or JRuby isn’t optimized to run on OpenJ9. Perhaps all of the above.
Final Thoughts
Alright, I hope this was interesting for y’all!
What did we learn? TruffleRuby still has the best “warm” performance by a mile, warmup is getting better but can still be tricky (–> unexpected slowdowns late into the process). The JIT for CRuby seems to get better continuously and has me a bit excited. CRuby performance has caught up to JRuby out of the box (without invokedynamic). JRuby with invokedynamic is still the second fastest Ruby implementation though.
It’s also interesting to see that every Ruby implementation has at least one switch (–jit, –jvm, invokedynamic) that significantly alters performance characteristics.
Please, also don’t forget the typical grain of salt: This is one benchmark, with one rather specific use case run on one machine. Results elsewhere might differ greatly.
What else is there? Promising to redo the benchmark next year would be something, but my experience tells me not to 😉
There’s an Enterprise version of GraalVM with supposedly good performance gains. Now, I won’t be spending money but you can evaluate it for free after registering. Well, if I ever manage to fix my Oracle login and get Oracle’s permission to publish the numbers I might (I’m fairly certain I can get that though 🙂 ). I also heard rumours of some CLI flags to try with TruffleRuby to get even better numbers 🤔
Finally, this benchmark has only looked at run times which is most often the most interesting value. However, there are other numbers that could prove interesting, such as memory consumption. These aren’t as easy to break down so neatly (or I don’t know how to). Showing the maximum amount of memory consumed during the measurement could be helpful though. As some people can tell you, with Ruby it can often be that you scale up your servers due to memory constraints not necessary CPU constraints.
I’d also be interested in how a new PC (planned purchase within a year!) affects these numbers.
So, there’s definitely some future work to be done here. Anything specific you want to see? Please let me know in the comments, via Twitter or however you like. Same goes for new graph types, mistakes I made or what not – I’m here to learn!
Leave a Reply
