
在360网络安全学院已经学习了很久了,对Web安全已经建立了一个系统的认识。而且自己一直对人工智能、机器学习这类东西蛮感兴趣的,而且一直在看《Hands On Machine Learning with Scikit Learn and TensorFlow》这本书,所以在做毕业设计时第一时间就想到了把机器学习和Web安全结合在一起。
现在有各种各样的马,一句话,加密,混淆。普通的WebShell检测工具发挥的作用已经适应不了险恶的网络环境了,因此就必须有更加厉害的识别工具。 下面是我对机器学习识别WebShell的一些思路,希望大家可以互通有无,共同进步。
首先从github上下载了很多木马文件,然后从一些开源CMS中提取出php文件。(如 CodeIgniter,Joomla,Mambo,phpmyadmin,typecho,WordPress)
预处理
将文件夹中的图像,js脚本,css样式筛选出去
import os from sklearn.base import BaseEstimator, TransformerMixin class filters(BaseEstimator, TransformerMixin): def transform(self, path): newList = [] filterExt = ["jpg", "jpeg", "png", "git", "js", "css", "ico", "jar", "md", "sql", "json", "twig"] for root, dirs, files in os.walk(path): for completeName in files: fileName, extension = os.path.splitext(completeName) if extension.lower() not in filterExt: newList.append(os.path.join(root, completeName)) return newList不能给机器太大压力
将文件统一编码为utf-8
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList方便后面对文件的处理和特征提取
对列表中的文件进行去重
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list重复的文本会对机器的学习造成负面影响
将不在列表中的文件从buf中移除
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")创建文件预处理流水线对文件进行处理
from sklearn.pipeline import Pipeline file_transform = Pipeline([ ('filters', filters()), ('convert_encode', convert_encode()), ('removal', removal()), ('clearn', clearn()) ]) path = "sample/" file_transform.transform(path)12732 个文件中 2811 个文件被统一编码,所有处理后的文件被放到buf下
一共有 4885 个重复文件,已从列表中去除
删除了 4885 个无用文件
损失了2/3的木马文件
创建特征
主要调用了NeoPI的接口,它使用各种统计方法来检测文本/脚本文件中的混淆和加密内容。
统计文章长度
import os class getLen: def calculate(self,data,filename): if not data: return 0 length = 0 for i in data: length = length + len(i) return length正常网站的文件的文章篇幅不会太大也不会太小,但WebShell有的很长,有的很短,可以有效地从文件中分离出大马和小马
计算文章的熵值
import math class Entropy: def __init__(self): self.results = [] def calculate(self,data,filename): if not data: return 0 entropy = 0 self.stripped_data =data.replace(' ', '') for x in range(256): p_x = float(self.stripped_data.count(chr(x)))/len(self.stripped_data) if p_x > 0: entropy += - p_x * math.log(p_x, 2) self.results.append({"filename":filename, "value":entropy}) return entropy因为单词的组成都是有规律的,所以正常的文章熵值不会太大也不会太小,而WebShell的熵值会因为加密而产生浮动,可以把正常文件和加密马分离出来
统计文章最长的单词
import re class LongestWord: def __init__(self): self.results = [] def calculate(self,data,filename): if not data: return "", 0 longest = 0 longest_word = "" words = re.split("[/s,/n,/r]", data) if words: for word in words: length = len(word) if length > longest: longest = length longest_word = word self.results.append({"filename":filename, "value":longest}) return longest正常的文章,最长单词的长度不会超过20吧,但是WebShell就不一定了,由于加密,或者存在提权的 payload 最长单词会变得很长
统计文章中恶意词汇的数量
class SignatureNasty: def __init__(self): self.results = [] def calculate(self, data, filename): if not data: return "", 0 valid_regex = re.compile('(eval/(|file_put_contents|base64_decode|exec/(|passthru|popen|proc_open|pcntl|assert/(|system/(|shell)', re.I) matches = re.findall(valid_regex, data) self.results.append({"filename":filename, "value":len(matches)}) return len(matches)一般的文件不会存在太多的文件操作,命令执行函数,但WebShell会
计算文章的可压缩比例
import zlib class Compression: def __init__(self): self.results = [] def calculate(self, data, filename): if not data: return "", 0 compressed = zlib.compress(data.encode('utf-8')) ratio = float(len(compressed)) / float(len(data)) self.results.append({"filename":filename, "value":ratio}) return ratio有些木马会把自己的内容压缩或者编码,加密,这些都会一定程度上的影响文章的可压缩比例,所以这个特征也有一定的参考
将特征提取过程打包
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList0
处理数据
将数据从文件夹读取出来
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList1
创建标签
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList2
计算各个文件的特征值
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList3
将特征集合在一起,生成一个DataFrame
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList4
查看前五条数据
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList5
查看数据的整体状况
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList6
查看数据中两种数据所占比例
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList7
有三个特征格式不正确,进行转换
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList8
分析数据
五个特征对于两类文件的平均值
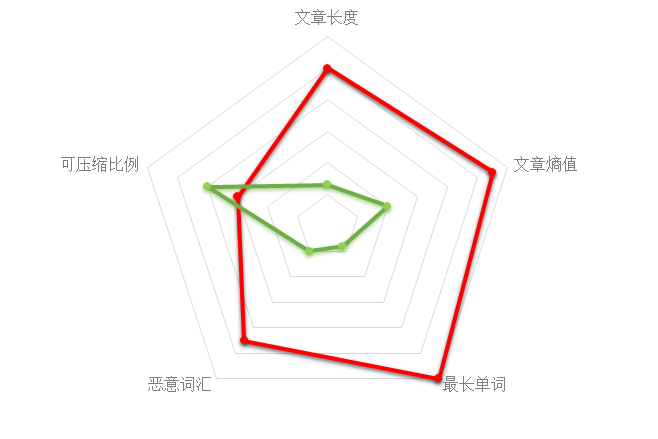
红色代表WebShell,绿色代表正常文件,下面雷同
导入画图的库
import chardet class convert_encode(BaseEstimator, TransformerMixin): def transform(self, lists): num = 0 newList = [] for x in lists: with open(x, "rb") as f: content = f.read() encode = chardet.detect(content)['encoding'] if encode != "ascii": content = content.decode("utf-8", "ignore") num += 1 else: content = content.decode(encode, "ignore") filePath, fileName = os.path.split(x) bufPath = "buf/" + filePath[7:] if not os.path.exists(bufPath): os.makedirs(bufPath) with open(bufPath + "/" + fileName, "w") as f: f.write(content) newList.append(bufPath + "/" + fileName) print(len(lists), "个文件中", str(num), "个文件被统一编码,所有处理后的文件被放到buf下") return newList9
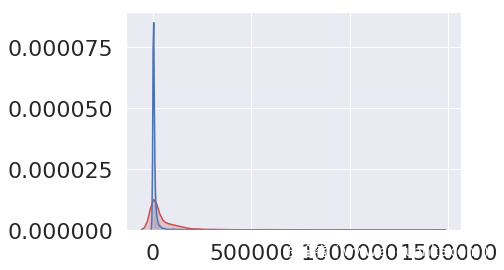
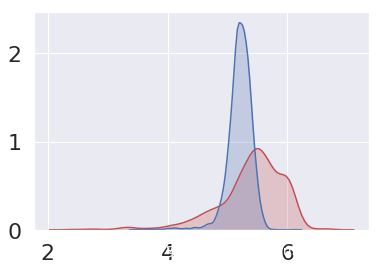
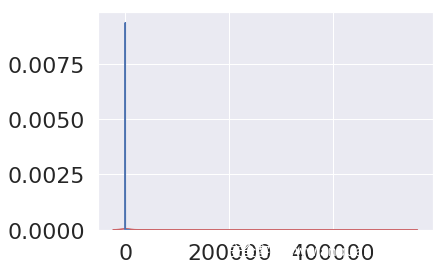
将各个特征以图形化的界面展现出来
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list0
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list1
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list2
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list3
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list4
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list5

import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list6
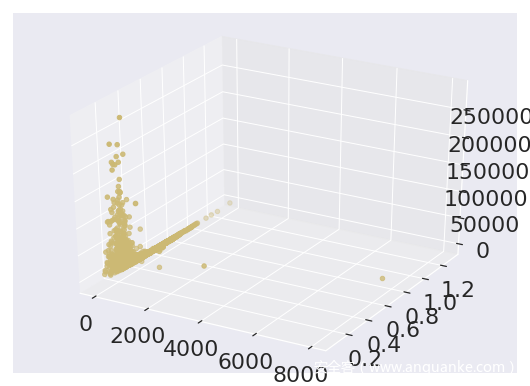
从图片中可以看出大部分的WebShell还是可以被区别出来的
计算出各个参数之间的皮尔逊系数
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list7
按shell占比例将数据均匀分开
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list8
将X,Y分离
import hashlib def get_md5(file_path): md5_obj = hashlib.md5() with open(file_path, 'rb') as f: md5_obj.update(f.read()) return md5_obj.hexdigest() class removal(BaseEstimator, TransformerMixin): def transform(self, all_files): num = 0 all_md5 = [] new_list =[] for files in all_files: file_md5 = get_md5(files) if file_md5 not in all_md5 and (file_md5 != -1): all_md5.append(file_md5) new_list.append(files) else: num += 1 print("一共有", str(num), "个重复文件,已从列表中去除") return new_list9
载入性能考核函数,并对结果进行评定
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")0
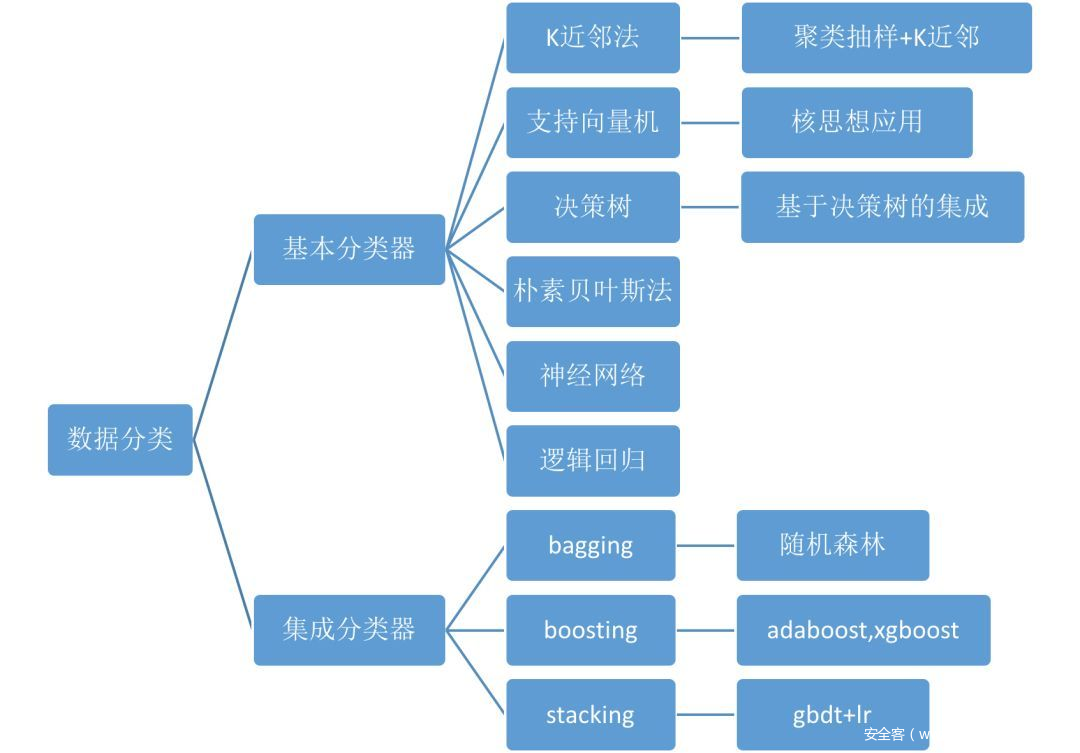
分类算法介绍
最有影响力的十大数据挖掘算法中包含的分类算法
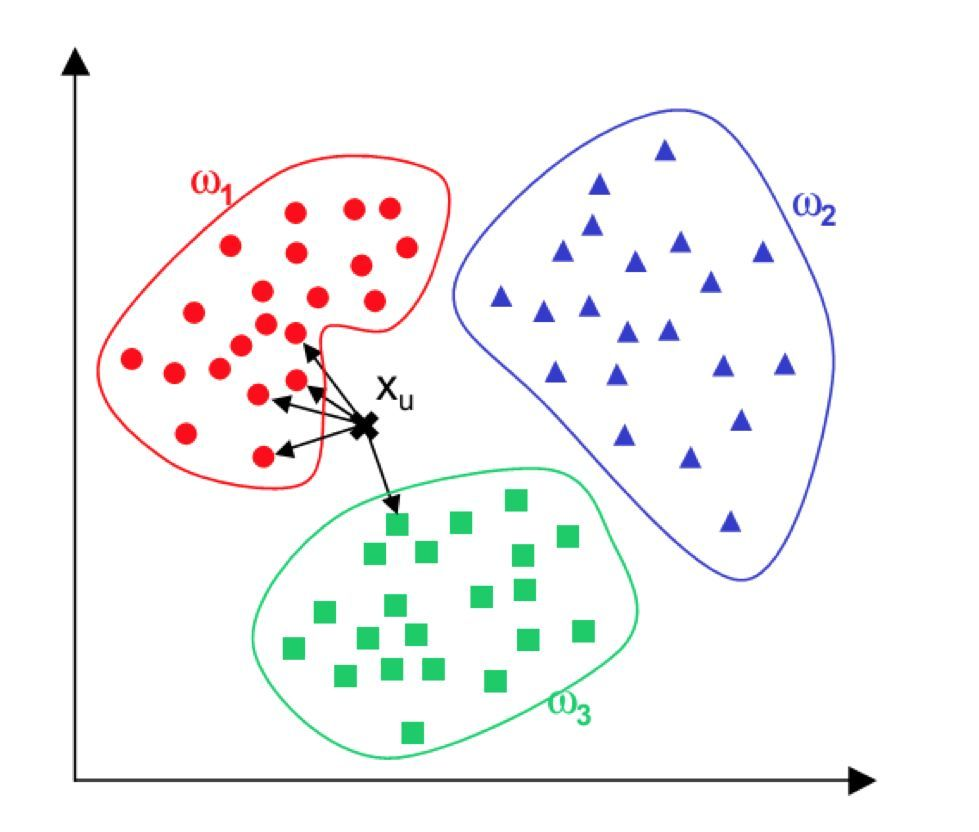
k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
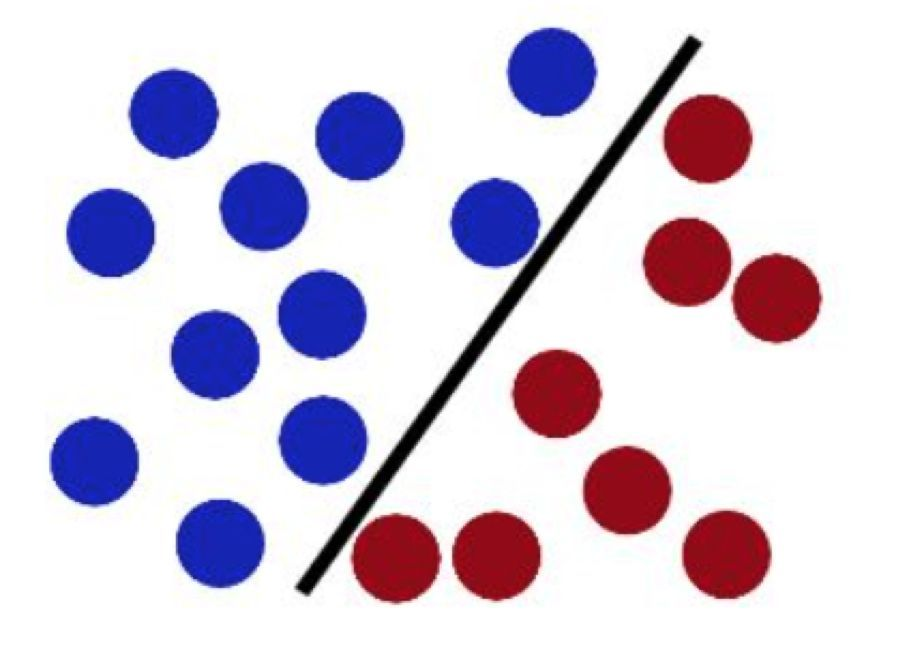
SVM法
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
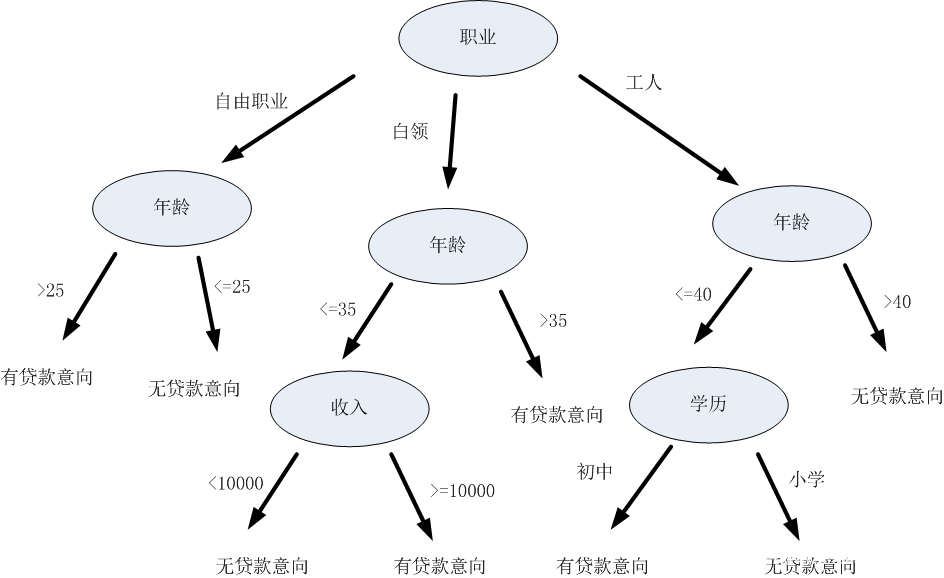
决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。是一种十分常用的监管学习式分类方法。
朴素贝叶斯
朴素贝叶斯方法是一种监督学习算法,它基于贝叶斯定理给定类变量值的每对特征之间的条件独立性的“简单”假设。在给定类变量$y$和从属特征向量$x{1}$到$x{n}$,贝叶斯定理表明了以下关系:
$P(y /mid x1, /dots, xn) = /frac{P(y) P(x1, /dots xn /mid y)} {P(x1, /dots, xn)}$
使用简单的条件独立假设
$P(xi | y, x1, /dots, x{i-1}, x{i+1}, /dots, xn) = P(xi | y),$
对于所有$i$,这种关系被简化为
$P(y /mid x1, /dots, xn) = /frac{P(y) /prod{i=1}^{n} P(xi /mid y)} {P(x1, /dots, xn)}$
由于$P(x1, /dots, xn)$在输入时是常数,我们可以使用以下分类规则:
$/begin{align}/begin{aligned}P(y /mid x1, /dots, xn) /propto P(y) /prod{i=1}^{n} P(xi /mid y)//Downarrow//hat{y} = /arg/maxy P(y) /prod{i=1}^{n} P(x_i /mid y),/end{aligned}/end{align}$
我们可以使用最大后验(MAP)估计来估计$$P(y)和$P(x_i /mid y)$; 前者是训练集中$y$类的相对频率。
神经网络
神经网络由“神经元”构成,一个“神经元”是一个运算单元f,该运算单元在神经网络中称作激活函数,激活函数通常设定为sigmoid函数(也可以设为其他函数),它可以输入一组加权系数的量,对这个量进行映射,如果这个映射结果达到或者超过了某个阈值,输出一个量。

逻辑回归
逻辑回归的模型是一个非线性模型,sigmoid函数,又称逻辑回归函数。但它其实是基于线性回归模型,因为除去sigmoid映射函数关系,其他的步骤,算法都是线性回归的。所以可以说,逻辑回归,都是以线性回归为理论支持的。

随机森林
随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。随机森林是集成学习思想下的产物,将许多棵决策树整合成森林,并合起来用来预测最终结果。

adaboost
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特征,并放在关键的训练数据上面。
xgboost
该算法思想就是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。
gbdt+lr
GBDT算法的图示部分形如一棵倒过来的树,其根部即代表训练GBDT算法的原始数据集,经过树算法对原始数据的切分,可得到代表不同新特征的叶子节点。再将GBDT所得的叶子节点输入LR算法,经过线性分析和sigmoid映射,即可得到模型分类结果。

分类算法尝试
K近邻法
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")1
k近邻:
精度:0.8494983277591973
召回率:0.6397984886649875
综合得分:0.7298850574712645
支持向量机
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")2
/home/cances/.local/lib/python3.6/site-packages/sklearn/svm/base.py:196: FutureWarning: The default value of gamma will change from ‘auto’ to ‘scale’ in version 0.22 to account better for unscaled features. Set gamma explicitly to ‘auto’ or ‘scale’ to avoid this warning.
“avoid this warning.”, FutureWarning)
支持向量机:
精度:0.9824561403508771
召回率:0.28211586901763225
综合得分:0.4383561643835617
决策树
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")3
决策树:
精度:0.9149484536082474
召回率:0.8942065491183879
综合得分:0.9044585987261146
朴素贝叶斯分类
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")4
贝叶斯分类器:
精度:0.9148936170212766
召回率:0.4332493702770781
综合得分:0.5880341880341879
随机森林
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")5
随机森林:
精度:0.9625668449197861
召回率:0.906801007556675
综合得分:0.933852140077821
ADABOOST
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")6
AdaBoost:
精度:0.9105691056910569
召回率:0.8463476070528967
综合得分:0.877284595300261
XGBOOST
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")7
/home/cances/.local/lib/python3.6/site-packages/xgboost/core.py:587: FutureWarning: Series.base is deprecated and will be removed in a future version
if getattr(data, ‘base’, None) is not None and /
/home/cances/.local/lib/python3.6/site-packages/xgboost/core.py:588: FutureWarning: Series.base is deprecated and will be removed in a future version
data.base is not None and isinstance(data, np.ndarray) /
xgboost:
精度:0.9545454545454546
召回率:0.8992443324937027
综合得分:0.9260700389105059
GBDT+LR
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")8
GBDT :
精度:0.9351351351351351
召回率:0.871536523929471
综合得分:0.9022164276401564
投票算法
class clearn(BaseEstimator, TransformerMixin): def fit(self, lists): return self def transform(self, lists): num = 0 for root, dirs, files in os.walk("buf/"): for i in files: completeName = os.path.join(root, i) if completeName not in lists: os.remove(completeName) num += 1 print("删除了", str(num), "个无用文件")9
Voting:
精度:0.9624664879356568
召回率:0.9042821158690176
综合得分:0.9324675324675323
对随机森林进行参数优化测试
Estimators参数调整
from sklearn.pipeline import Pipeline file_transform = Pipeline([ ('filters', filters()), ('convert_encode', convert_encode()), ('removal', removal()), ('clearn', clearn()) ]) path = "sample/" file_transform.transform(path)0

features参数调整
from sklearn.pipeline import Pipeline file_transform = Pipeline([ ('filters', filters()), ('convert_encode', convert_encode()), ('removal', removal()), ('clearn', clearn()) ]) path = "sample/" file_transform.transform(path)1

尾声
确定最终模型并将训练结果存储起来
from sklearn.pipeline import Pipeline file_transform = Pipeline([ ('filters', filters()), ('convert_encode', convert_encode()), ('removal', removal()), ('clearn', clearn()) ]) path = "sample/" file_transform.transform(path)2
读取模型的方法
from sklearn.pipeline import Pipeline file_transform = Pipeline([ ('filters', filters()), ('convert_encode', convert_encode()), ('removal', removal()), ('clearn', clearn()) ]) path = "sample/" file_transform.transform(path)3
最后还有一个验证集部分,因为代码写的比较乱就不放上来了,结果还不错,大部分马都没能逃过模型的“法眼”。除了网站安装文件被误报其他的没有毛病了。安装文件本来也就有很大的权限,而且正常运营的网站也不应该存在安装文件,防止被重置网站,这样我的模型还有了一个可以检测安装文件是否被删除的附加功能,很满意。。。。