前言
在参考项目源码的基础上对XP3引擎进行深入逆向分析
XP3逆向初试
在exe的plugin目录下看到.tpm文件
die看看确实是一个dll 改了个后缀罢了…
而且在导出表部分发现是以xp3dec.tpm的name
一样的对exe执行exe设好三个条件断点
CreateFile
文件读取: {utf16@[esp+4]} ReadFile
读取文件: 句柄:{[esp+4]} 缓冲:{[esp+8]} 字节数:{[esp+C]} SetFilePointer
设置文件指针: 句柄:{[esp+4]} 偏移量:{[[esp+C]]}{[esp+8]} 基准:{[esp+10]} 这里要改为utf8才能正常显示
然而这题由于是调用的dll来解密 不像万华镜是直接引擎解密 所以这样下断点分析很难看出端倪
那就从.tpm入手 string找到关键字符串void ::TVSetXP3ArchiveExtractionFilter(tTVPXP3ArchiveExtractionF
交叉引用找到V2Link部分 正是dll的导出函数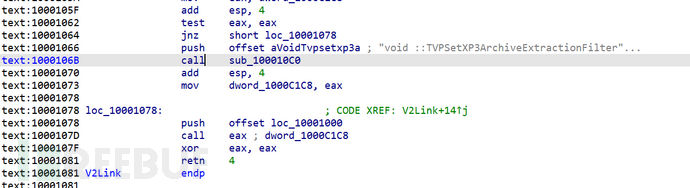
逐个跟踪 跟踪到这个push offset loc_10001000
点过去发现IDA并没有完全识别
text:10001000 loc_10001000: ; DATA XREF: V2Link:loc_10001078↓o .text:10001000 push esi .text:10001001 mov esi, [esp+8] .text:10001005 cmp dword ptr [esi], 18h .text:10001008 jz short loc_1000102C .text:1000100A mov eax, dword_1000C2CC .text:1000100F test eax, eax .text:10001011 jnz short loc_10001025 .text:10001013 push offset aVoidTvpthrowex ; "void ::TVPThrowExceptionMessage(const t"... .text:10001018 call sub_100010C0 .text:1000101D add esp, 4 .text:10001020 mov dword_1000C2CC, eax .text:10001025 .text:10001025 loc_10001025: ; CODE XREF: .text:10001011↑j .text:10001025 push offset aIncompatibleTt ; "Incompatible tTVPXP3ExtractionFilterInf"... .text:1000102A call eax ; dword_1000C2CC .text:1000102C .text:1000102C loc_1000102C: ; CODE XREF: .text:10001008↑j .text:1000102C xor eax, eax .text:1000102E cmp [esi+10h], eax .text:10001031 jbe short loc_1000104B .text:10001033 .text:10001033 loc_10001033: ; CODE XREF: .text:10001049↓j .text:10001033 mov ecx, [esi+0Ch] .text:10001036 mov dl, [ecx+eax] .text:10001039 xor dl, [esi+14h] .text:1000103C add ecx, eax .text:1000103E xor dl, 0CDh .text:10001041 add eax, 1 .text:10001044 mov [ecx], dl .text:10001046 cmp eax, [esi+10h] .text:10001049 jb short loc_10001033 .text:1000104B .text:1000104B loc_1000104B: ; CODE XREF: .text:10001031↑j .text:1000104B pop esi .text:1000104C retn 4 .text:1000104C ; --------------------------------------------------------------------------- .text:1000104F align 10h .text:10001050 ; Exported entry 1. V2Link 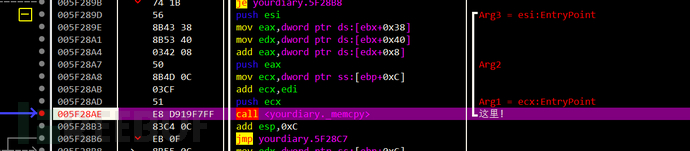
/* tTVPXP3ExtractionFilterInfo のメンバは以下の通り * SizeOfSelf : 自分自身の構造体のサイズ * Offset : "Buffer" メンバが指し示すデータが、 * : アーカイブに格納されているそのファイルの先頭からの * : どのオフセット位置からのものか、を表す * Buffer : データ本体 * BufferSize : "Buffer" メンバの指し示すデータのサイズ(バイト単位) * FileHash : ファイルの暗号化解除状態でのファイル内容の32bitハッシュ */ 逆向经验知道esi经常来传结构体 汇编已经很清晰了:
[esi+0xC]: 数组偏移 DWORD [esi+0x10]:size DWORD [esi+0x14]:xor的key值 DWORD 至于0~0xC的部分是什么还不是很清楚
看官方结构体的意思应该是
[esi+0x0]: 结构体大小 DWORD [esi+0x4]: ? QWORD 但这个QWORD后面动调看每次都是0?
总:
[esi+0x0]: 结构体大小 DWORD [esi+0x4]: ? QWORD [esi+0xC]: 数组偏移 DWORD [esi+0x10]:size DWORD [esi+0x14]:xor的key值 DWORD x32dbg在10001000下个断点跟踪 看内存布局
18 00 00 00 00 00 00 00 00 00 00 00 3A FD 19 00
02 00 00 00 D4 88 EA AC 88 00 00 00 02 00 00 00
对应着看就很清晰了
现在关注的点就是程序是在哪一步读取的数据
硬件断点定位到前面关注过的一处memcpy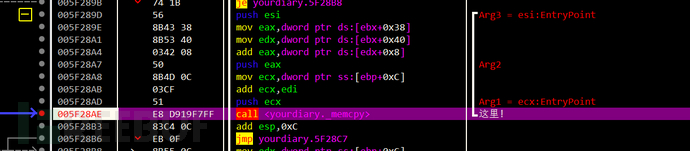
但各个内存数据对应关系不是很直接
data.xp3读的不是readfile读的 readfile读的与memcpy的有偏移
猜测应该是还有个结构体成员等来读取偏移
这个偏移的计算有点复杂
mov eax [ebx+0x38] mov edx [ebx+0x40] add eax [edx+0x8] => [ebx+0x38]+[[ebx+0x40]+0x8] 间接调用找到对应内存发现并不是完全的对应关系 也就是在加密/解密和源数据之间还有没考虑到的地方 – 压缩与解压缩
而以前接触的引擎都没有压缩与解压缩的步骤 这就使得了解XP3文件结构尤为关键
XP3引擎研究
XP3文件格式
基本思路&&工具介绍
整体思路:
合理利用已有开源工具
用引擎不同打包方式得到文件进行对比分析
掌握的情报:
XP3支持包含文件和目录
XP3支持存储文件名
XP3支持针对文件的压缩
XP3支持基于文件的加密
XP3支持对索引的压缩
工具:
010 Editor
GARbro Github开源项目
krkr官方xp3打包器 在KiriKiri2开发包下
krkr-xp3 一个开源的XP3解包打包器 方便用来研究XP3文件格式 跟一些elf_parser很类似的功能
GARbro
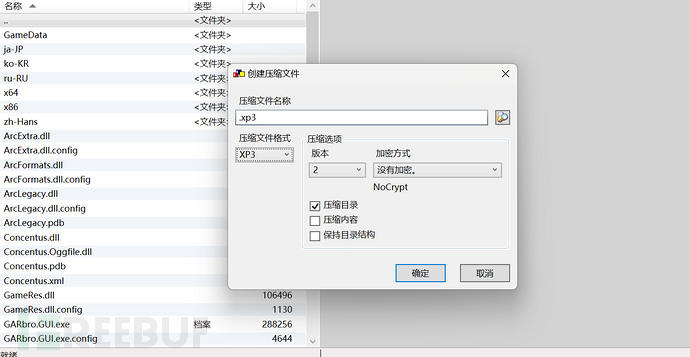
官方release:
实验
XP3压缩&加密技术
GARbro的zlib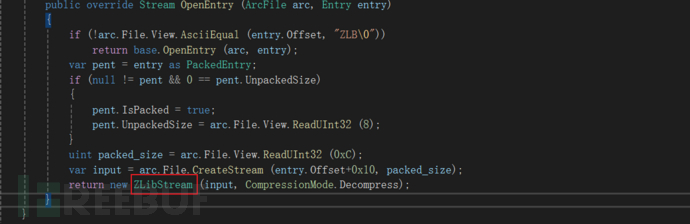
krkrxp3的zlib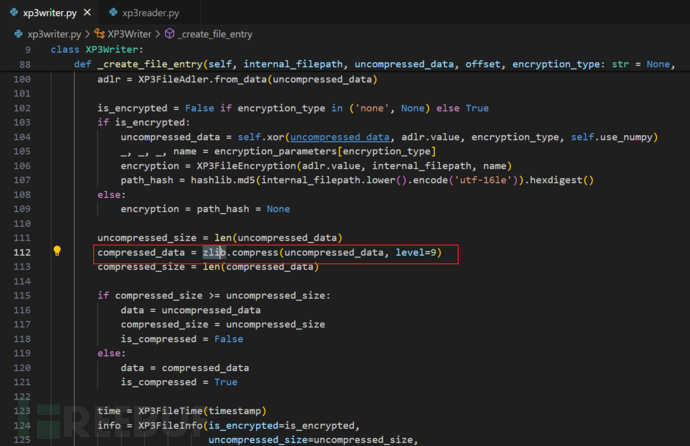
这里可以看到zlib压缩等级为9
用GARbro和官方封包exe分别打包一次
GARbro选择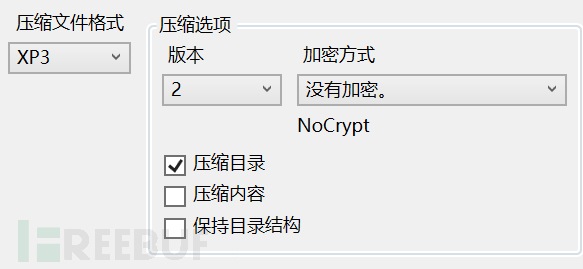
可以发现GARbro的Version2跟官方是匹配的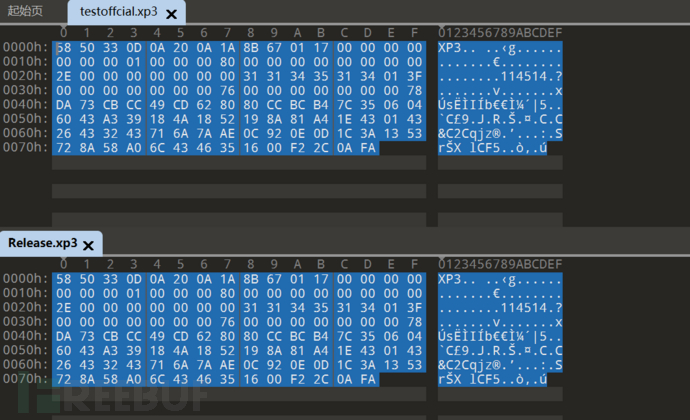
接下来用bandizip进行不同压缩算法的尝试 找到xp3采用的压缩类型
经过尝试 发现gz的deflate模式开最大压缩比能够与xp3匹配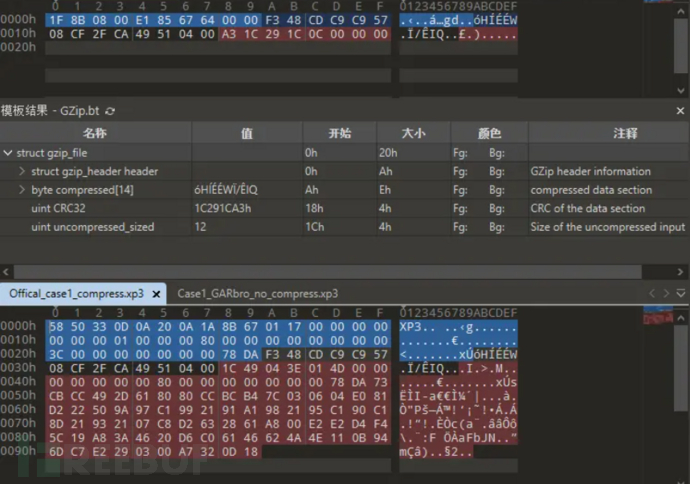
确定了压缩类型 我们接下来就需要横向对比来找类似的索引结构
多选几种类型的文件GARbro进行压缩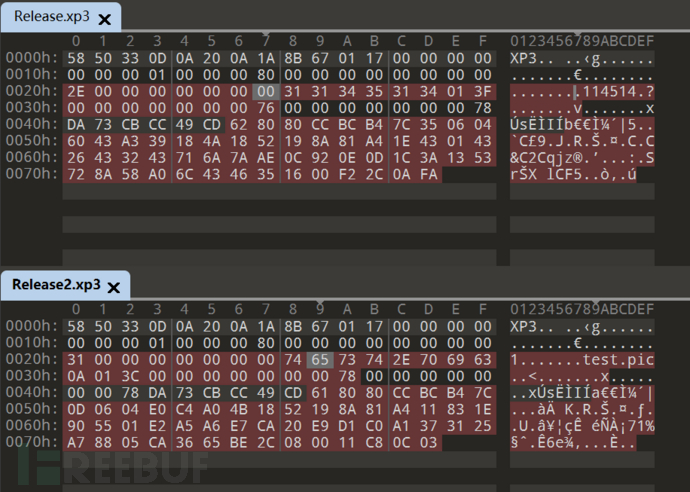 )
)
看自己压缩的小文件看不出什么 我们横向对比一下大型的XP3文件
大致发现都是以00 00 00 00 00 00 00 78 DA 73 CB CC 49作为分隔
对应的结构
官方release的在中文系统不那么兼容 采用GARbro封包看(封包当前这个md文件)
三个压缩选项都不选择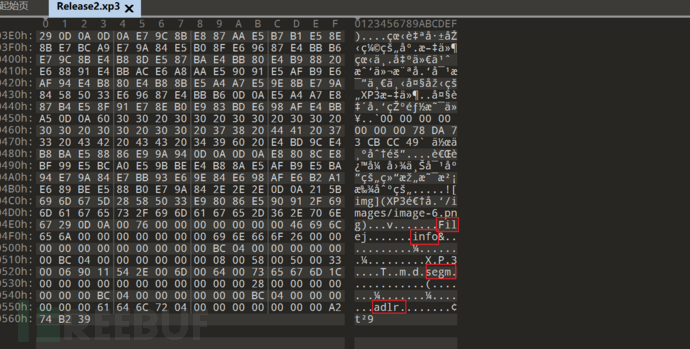
就能看到尾部的File``info``segm``adlr结构了
既然有压缩 那么很容易想到文件是否存在校验和
进行实验对比
建立两个md: 第一个写CRC or not 第二个写 CRC or not!
对比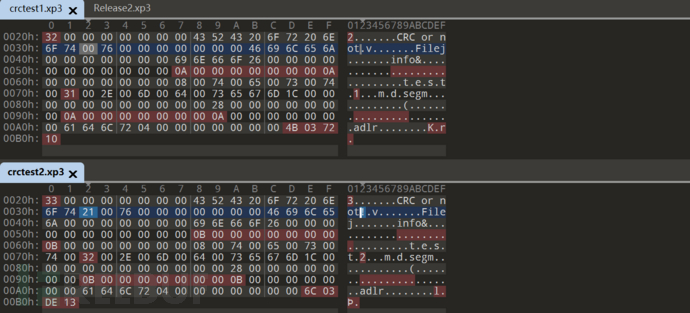
已经能看出一些迹象了
比如第一个文件内容长度 10=0A 第二个11=0B
再换成长度一样的 把第二个文件内容换为 CRC or nos
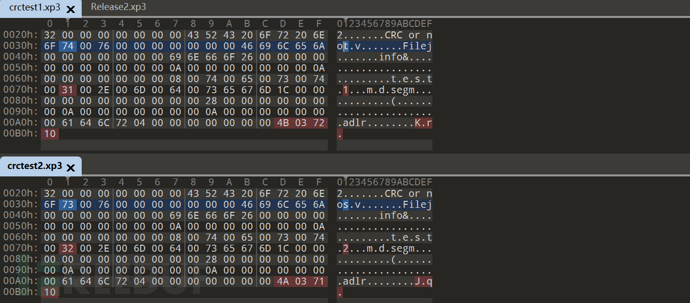
然而实验发现即使更改最后DWORD也不影响提取 所以应该是不存在校验解包过程的
接下来我们更改文件名不改文件内容实验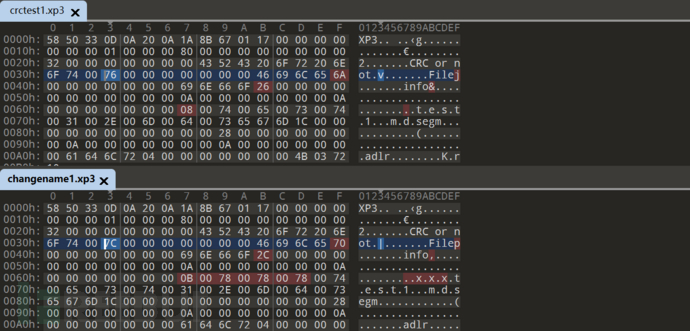
更改文件路径(多层文件夹)实验:
我将test1放入multifolder1-multifolder2 文件路径下
选择保持目录结构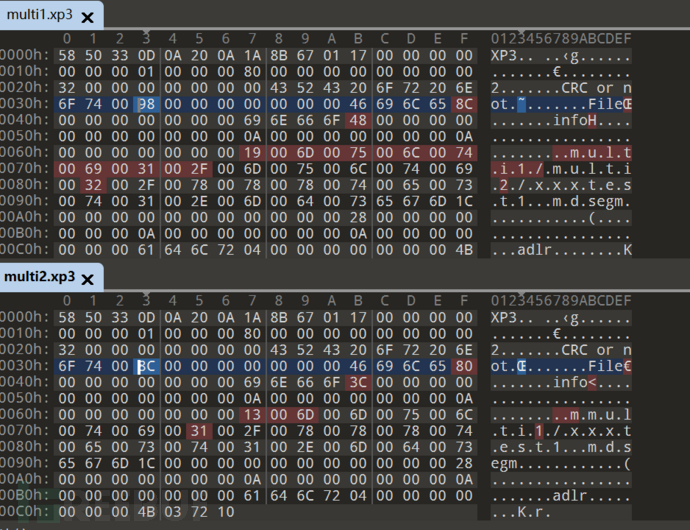
可以发现路径变化会影响某些结构值的变化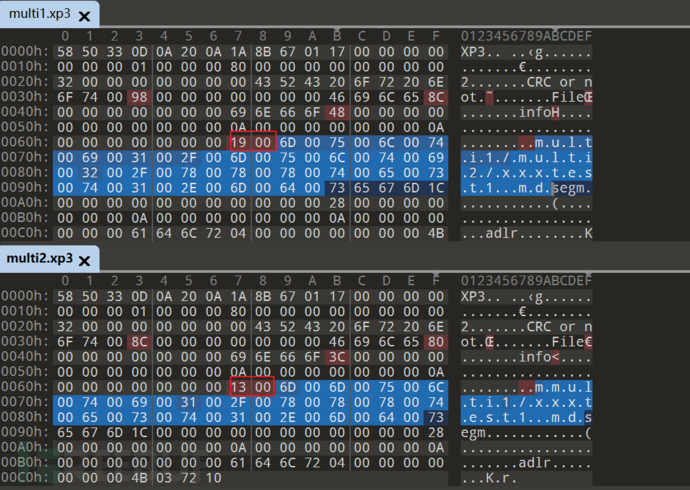
这两个值存储的就是路径的长度
前面文件内容后面不同的 98 8C 可能是后面文件的长度?
总结一下 目前为止 初步分析出了:
XP3对多层文件夹和路径都有对应处理
存在校验和 但是更改不会影响提取
xp3文件的路径部分,即文件结构和目录信息是通过尾部index中的info结构来记录的
选择加密方法前后对比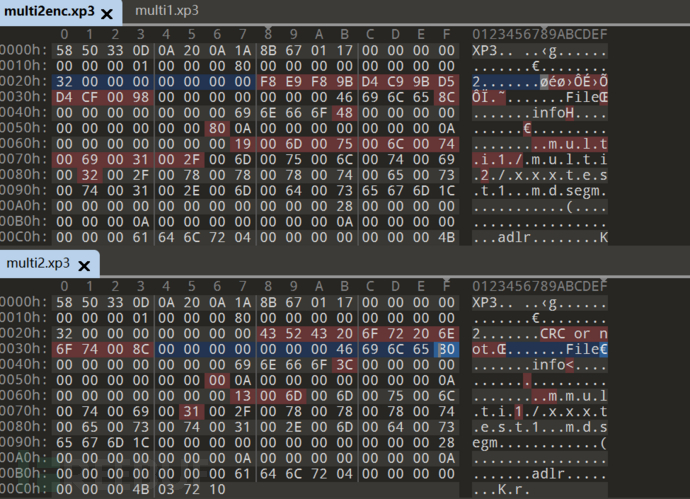
只对内容进行了加密 而且采用的都是简单xor…
下面结合已有的分析来看看GARbro对于xp3文件结构的处理
定位到ArcXP3.cs467行的Create函数
由函数名以及下面的功能可以知道这应该就是XP3的打包函数
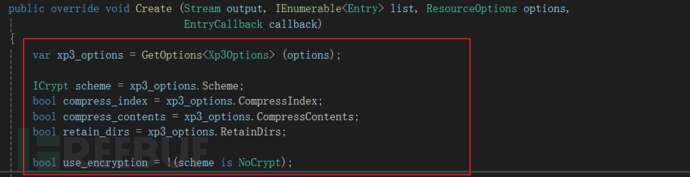
下面取出了结构
不压缩不加密的对应: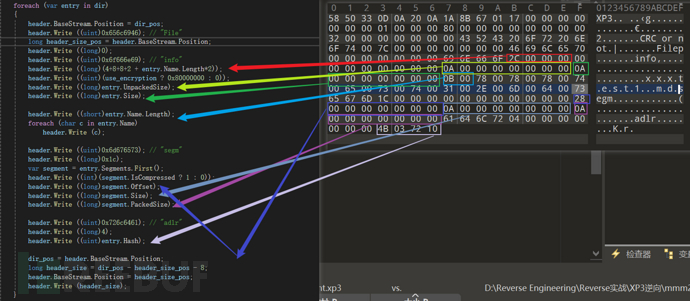
下面我们加密看看变化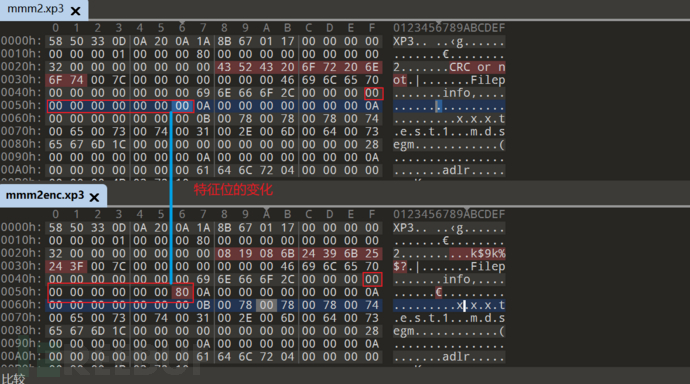
但实际压缩测试却并没有对应上?
压缩与不压缩: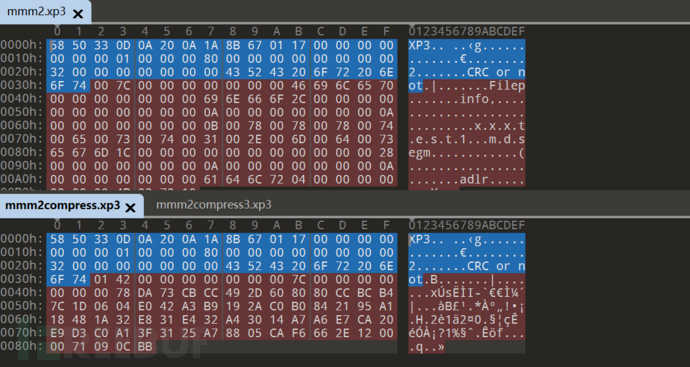
不同文件的压缩:
能发现一个类似标记的共有点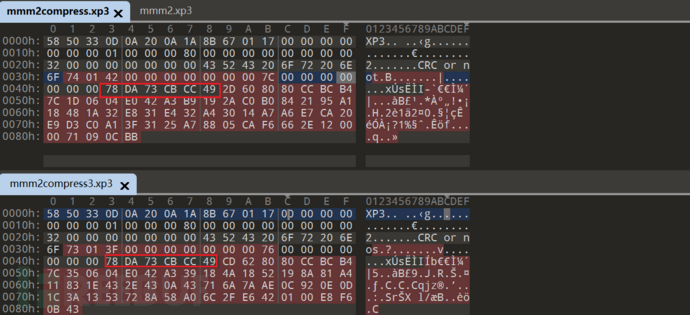
还不是很明了 继续看源码
分析从105行开始的TryOpen函数
从151行开始的一个大循环
代码都很清晰 注意一个点 像ReadInt32这种读了4Bytes后文件指针是往后移了的
while (-1 != header.PeekChar()) { uint entry_signature = header.ReadUInt32(); long entry_size = header.ReadInt64(); if (entry_size < 0) return null; dir_offset += 12 + entry_size; if (0x656C6946 == entry_signature) // File { var entry = new Xp3Entry(); while (entry_size > 0) { uint section = header.ReadUInt32(); long section_size = header.ReadInt64(); entry_size -= 12; if (section_size > entry_size) { if (section != 0x6f666e69) // info break; section_size = entry_size; } entry_size -= section_size; long next_section_pos = header.BaseStream.Position + section_size; switch (section) { case 0x6f666e69: // "info" if (entry.Size != 0 || !string.IsNullOrEmpty (entry.Name)) { goto NextEntry; // ambiguous entry, ignore } entry.IsEncrypted = 0 != header.ReadUInt32(); long file_size = header.ReadInt64(); long packed_size = header.ReadInt64(); if (file_size >= uint.MaxValue || packed_size > uint.MaxValue || packed_size > file.MaxOffset) { goto NextEntry; } entry.IsPacked = file_size != packed_size; entry.Size = (uint)packed_size; entry.UnpackedSize = (uint)file_size; if (entry.IsEncrypted || ForceEncryptionQuery) entry.Cipher = crypt_algorithm.Value; else entry.Cipher = NoCryptAlgorithm; var name = entry.Cipher.ReadName (header); if (null == name) { goto NextEntry; } if (entry.Cipher.ObfuscatedIndex && ObfuscatedPathRe.IsMatch (name)) { goto NextEntry; } if (filename_map.Count > 0) name = filename_map.Get (entry.Hash, name); if (name.Length > 0x100) { goto NextEntry; } entry.Name = name; entry.IsEncrypted = !(entry.Cipher is NoCrypt) && !(entry.Cipher.StartupTjsNotEncrypted && "startup.tjs" == name); break; case 0x6d676573: // "segm" int segment_count = (int)(section_size / 0x1c); if (segment_count > 0) { for (int i = 0; i < segment_count; ++i) { bool compressed = 0 != header.ReadInt32(); long segment_offset = base_offset+header.ReadInt64(); long segment_size = header.ReadInt64(); long segment_packed_size = header.ReadInt64(); if (segment_offset > file.MaxOffset || segment_packed_size > file.MaxOffset) { goto NextEntry; } var segment = new Xp3Segment { IsCompressed = compressed, Offset = segment_offset, Size = (uint)segment_size, PackedSize = (uint)segment_packed_size }; entry.Segments.Add (segment); } entry.Offset = entry.Segments.First().Offset; } break; case 0x726c6461: // "adlr" if (4 == section_size) entry.Hash = header.ReadUInt32(); break; default: // unknown section break; } header.BaseStream.Position = next_section_pos; } ... } ... } 对照010分析
可以看到File后面的70 就是info开始的整个结构的size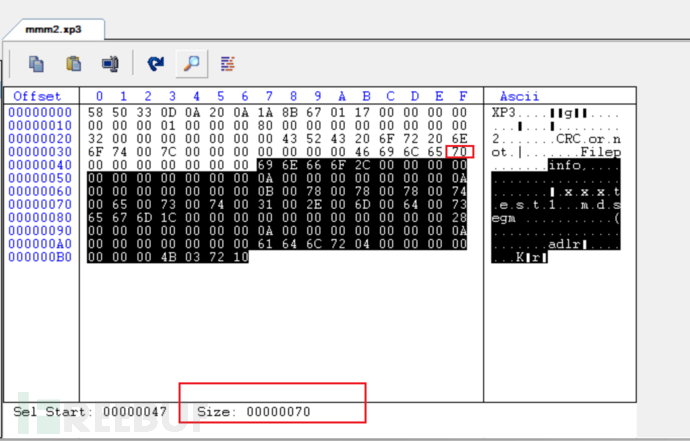
后面进行的就是各个section的switch check 还允许自定义section
当然 GARbro的代码跟实际krkr引擎执行的代码肯定还是有区别 先大致分析后面再调试对比
节区之间的关系已经清楚了 剩下的就是XP3 header是怎么索引到后面结构的?
进行多层次的xp3打包
层次结构:
-folder1
-folder2
-1.jpg
-2.png
-3.rtf
-folder3
-1.zip
-2.php
-22.rar
为了方便对比 这里再创建一个相同目录结构但是文件内容为空的进行对比
对比发现其实是将文件的所有内容都移到了开头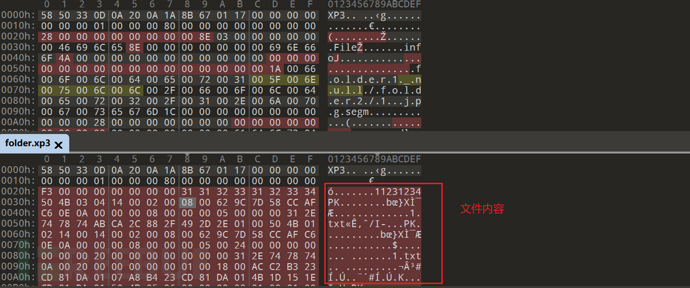
现在还剩的就是两个中间部分的数据值:
XP3header-> ? -> Data… -> ? -> Index&Section
对比一下可以发现这个值是文件内容过后的区域(index&section)的offset
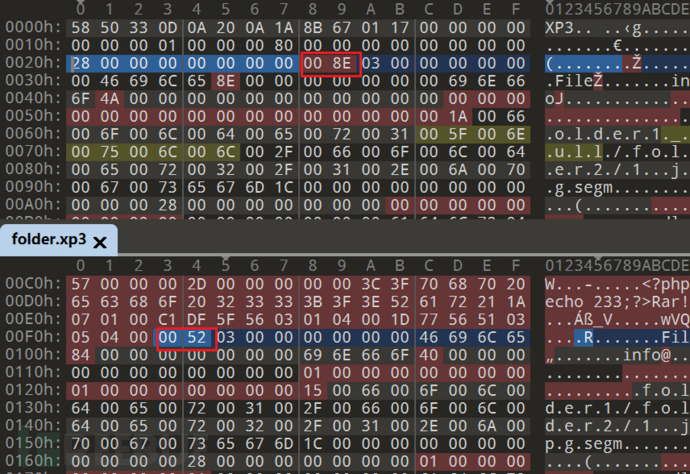
这下第一个间隙就清楚了: 一个int64 存放后续偏移地址
接下来再来看 XP3文件索引区域
会发现并没有对齐 结合前面压缩时发现有一个字节位 的0->1 猜测第一个字节就是标记是否压缩
那么接下来这个就对应的后面索引结构的大小(前面已经分析过了)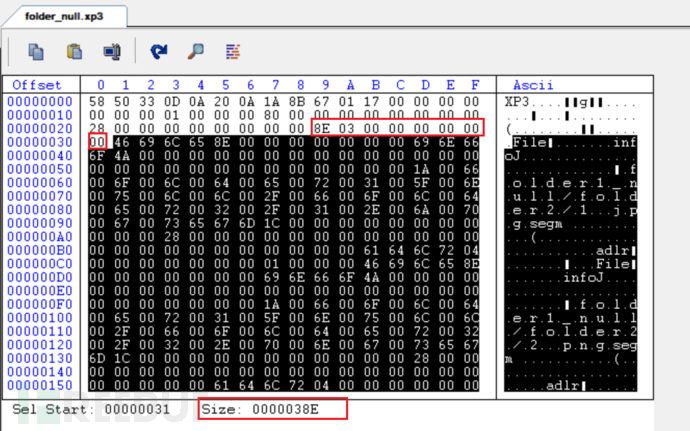
那对于压缩的情况呢?
可以发现很有趣的点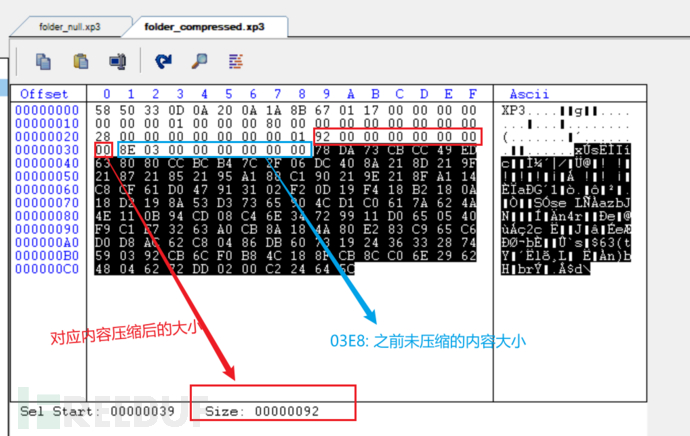
这就全部联系起来了 然后后面紧跟的是标识头
对比压缩加密发现标识头并没有变化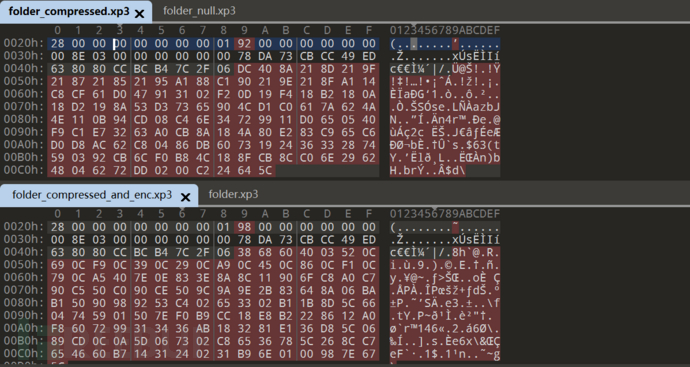
唯一区别在于加密的话是padding对齐了的
尝试换版本1压缩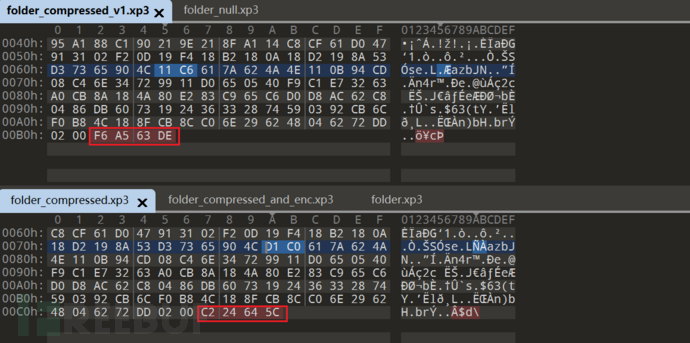
结尾的DWORD不一样 猜测可能是key/version ?
至此 XP3文件的结构已经大致明了了
接下来就是研究XP3封包中的压缩以及加密技术
先再来回顾一下索引的结构:
这里直接借图了(彩图更好看)
有四个字段跟大小有关:
entry.UnpackedSizeentry.Sizesegment.Sizesegment.PackedSize
但这里bandizip压缩的和GARbro的对不上….
先记录下大致思路:
GARbro压缩与bandizip gz deflate最大档位压缩对比发现重合
比较区别 发现添加了adlr 校验和
好吧发现原因了 不知道为什么GARbro将index整个一起压缩了
根据前面的结构提取出对应压缩的数据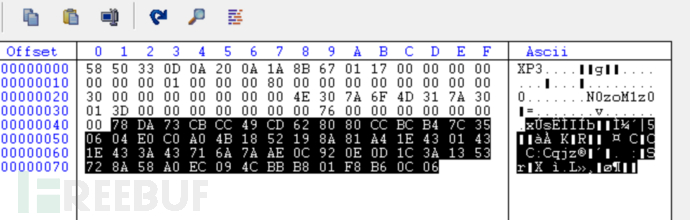
python解压缩(zlib)得到
然后替换回010
发现能吻合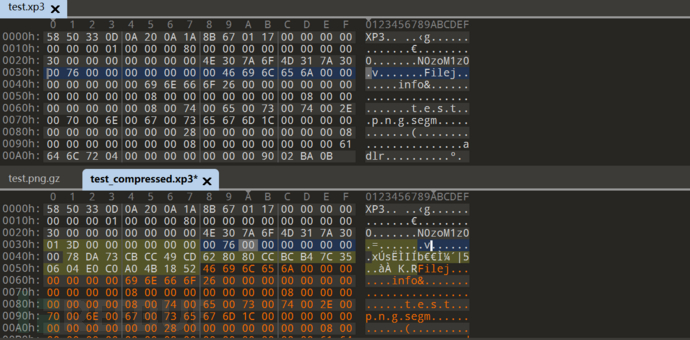
这里再解决这个部分最后一个疑问:
是先加密后压缩还是先压缩后加密?
理论分析:
我们看一个未加密的可视化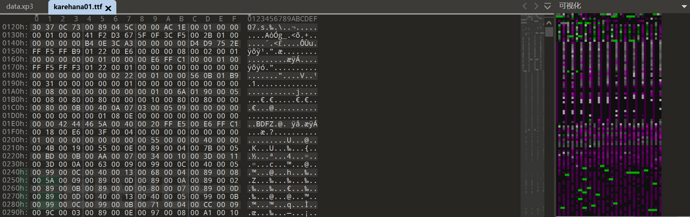
再看加密的: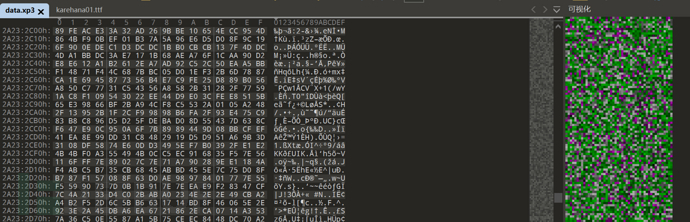
可以发现加密后数据较随机 而压缩是越规律压缩效果越好
所以理论上 先压缩后加密更好
那krkr呢?
我们做一个实验
建一个256个FF的文件 然后GARbro勾选压缩和加密 再分步骤对比
这里对比可以用计算Adle32校验和的方式
实验发现竟然是先加密再压缩…
然而压缩效果还很好…
从逆向角度能分析出一个点:
加密采用的是单字节的加密方式 – 大概率为简单异或
只有这样才不会改变文件内容的数据规律…
XP3引擎再逆向
接下来就正式进入逆向部分了: 对krkr引擎进行分析
某些xp3引擎是会调用plugins目录下的.tpm文件
tpm后缀实则是dll
两个导出函数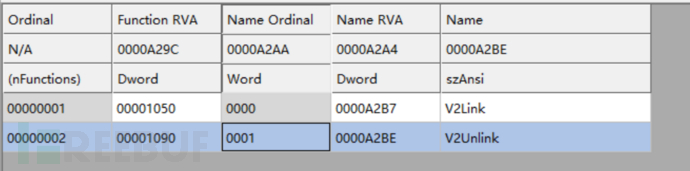
IDA分析:
V2Link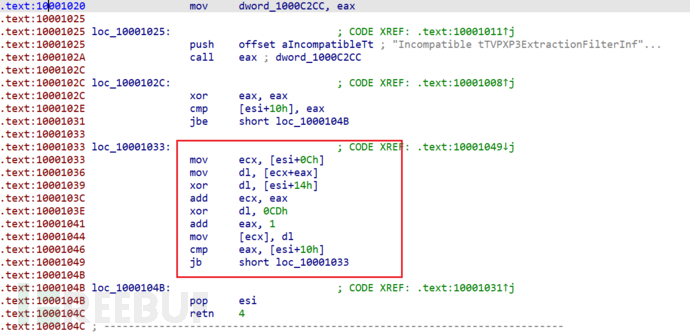
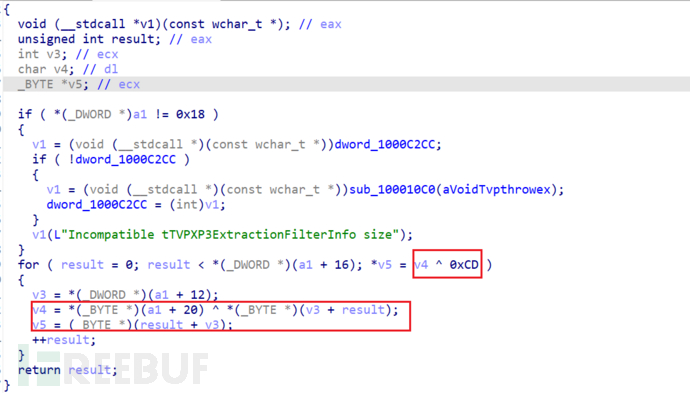
就是
v3[result] ^= 0xCD^(*(_BYTE *)(a1 + 20)) 官方源码: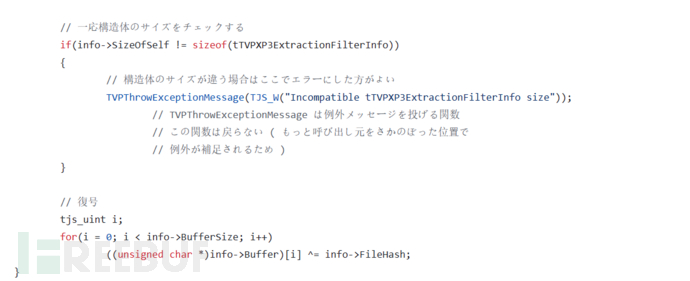
可以发现厂家在原基础上作了简单的key值修改
ida动调跟一根这个tpm
调用: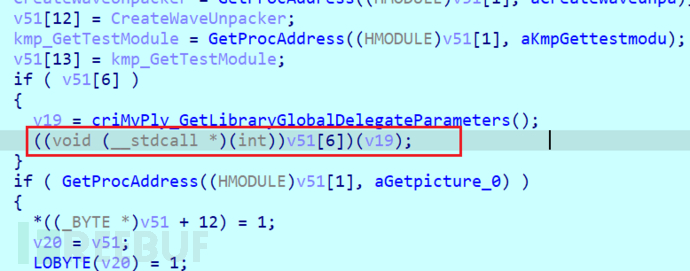
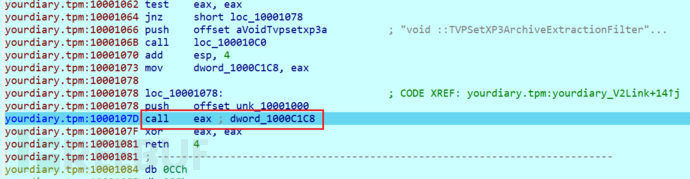
在引擎的sub_5ECD70也能找到对xp3结构的识别
_DWORD *__fastcall sub_5ECD70(int a1, _DWORD *a2, char a3, int a4) { char v4; // bl _DWORD *v5; // eax unsigned int v6; // edi _DWORD *v7; // eax _DWORD *v8; // esi int v9; // eax _DWORD *result; // eax int v11; // eax _DWORD *v12; // [esp-10h] [ebp-4004Ch] int v13; // [esp-Ch] [ebp-40048h] BYREF char v14[262144]; // [esp+0h] [ebp-4003Ch] BYREF char Buf2[15]; // [esp+40000h] [ebp-3Ch] BYREF char v16; // [esp+4000Fh] [ebp-2Dh] _DWORD *v17; // [esp+40010h] [ebp-2Ch] int (__cdecl ***v18)(_DWORD, _DWORD, _DWORD, _DWORD); // [esp+40014h] [ebp-28h] _EXCEPTION_REGISTRATION_RECORD *v19; // [esp+40018h] [ebp-24h] void *v20; // [esp+4001Ch] [ebp-20h] void *v21; // [esp+40020h] [ebp-1Ch] int *v22; // [esp+40024h] [ebp-18h] __int16 v23; // [esp+40028h] [ebp-14h] int v24; // [esp+40034h] [ebp-8h] v16 = a3; v17 = a2; v18 = (int (__cdecl ***)(_DWORD, _DWORD, _DWORD, _DWORD))a1; v21 = &unk_6ED0A8; v22 = &v13; v20 = &_ExceptionHandler; v19 = NtCurrentTeb()->NtTib.ExceptionList; v24 = 1; v23 = 8; sub_438664((int (__cdecl ***)(_DWORD, _DWORD, _DWORD, _DWORD))a1, 0i64); if ( byte_6ED095 ) { byte_6ED095 = 0; memcpy(&unk_7B2C9C, &unk_6ED088, 8u); memcpy(&unk_7B2CA4, &unk_6ED091, 3u); } Buf2[0] = 0; sub_4386A4((int)v18, (int)Buf2, 11); if ( Buf2[0] == 'M' && Buf2[1] == 'Z' ) { v4 = 0; v5 = v17; *v17 = 16; v5[1] = 0; sub_438664(v18, 16i64); while ( 1 ) { v7 = (_DWORD *)((int (__cdecl *)(int (__cdecl ***)(_DWORD, _DWORD, _DWORD, _DWORD), char *, int))(*v18)[1])( v18, v14, 0x40000); v8 = v7; if ( !v7 ) break; v6 = 0; v23 = 8; while ( 1 ) { v7 = (_DWORD *)memcmp(&unk_7B2C9C, &v14[v6], 0xBu); if ( !v7 ) break; v6 += 16; if ( (unsigned int)v8 <= v6 ) goto LABEL_10; } v7 = (_DWORD *)v6; v4 = 1; *(_QWORD *)v17 += v6; LABEL_10: if ( v4 ) break; *(_QWORD *)v17 += 0x40000i64; } if ( v4 ) goto LABEL_32; if ( v16 ) { if ( dword_7C1FF8 ) v9 = dword_7C1FF8; else v9 = dword_7C1FF4; v7 = (_DWORD *)sub_669CA0(v9, &a4); goto LABEL_32; } --v24; if ( a4 ) sub_408920((_DWORD *)a4); v23 = 8; result = 0; } else { if ( !memcmp(&unk_7B2C9C, Buf2, 0xBu) ) // XP3 { v7 = v17; *v17 = 0; v7[1] = 0; LABEL_32: LOBYTE(v7) = 1; v12 = v7; --v24; if ( a4 ) sub_408920((_DWORD *)a4); return v12; } if ( v16 ) { if ( dword_7C2004 ) v11 = dword_7C2004; else v11 = dword_7C2000; sub_669CA0(v11, &a4); } --v24; if ( a4 ) sub_408920((_DWORD *)a4); result = 0; } return result; } 基本逻辑跟GARbro是一样的 分MZ和普通xp3文件进行不同的解析
官方解密调用:
tjs_uint TJS_INTF_METHOD tTVPXP3ArchiveStream::Read(void *buffer, tjs_uint read_size) { EnsureSegment(); tjs_uint write_size = 0; while(read_size) { while(SegmentRemain == 0) { // must go next segment if(!OpenNextSegment()) // open next segment return write_size; // could not read more } tjs_uint one_size = read_size > SegmentRemain ? (tjs_uint)SegmentRemain : read_size; if(CurSegment->IsCompressed) { // compressed segment; read from uncompressed data in memory memcpy((tjs_uint8*)buffer + write_size, SegmentData->GetData() + (tjs_uint)SegmentPos, one_size); } else { // read directly from stream Stream->ReadBuffer((tjs_uint8*)buffer + write_size, one_size); } // execute filter (for encryption method) if(TVPXP3ArchiveExtractionFilter) { tTVPXP3ExtractionFilterInfo info(CurPos, (tjs_uint8*)buffer + write_size, one_size, Owner->GetFileHash(StorageIndex)); TVPXP3ArchiveExtractionFilter ( (tTVPXP3ExtractionFilterInfo*) &info ); } // adjust members SegmentPos += one_size; CurPos += one_size; SegmentRemain -= one_size; read_size -= one_size; write_size += one_size; } return write_size; } 采用循环读取数据 每次读取一个块来进行xor加密
可以发现这种如此简单的加解密完全不需要另起一个dll 可以隐藏在引擎代码流中
现在选取另一款xp3引擎进行逆向探究
这款引擎就没有解密dll了
可以静态翻代码翻到一些类似加解密的
还有这个设置的函数表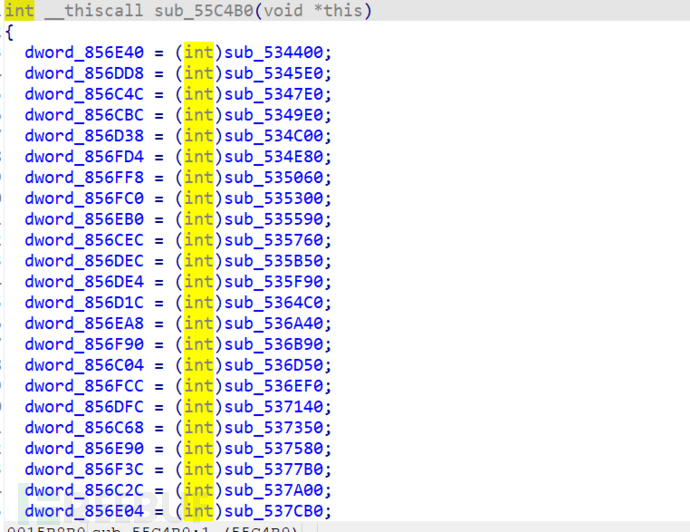
其中好多类似的函数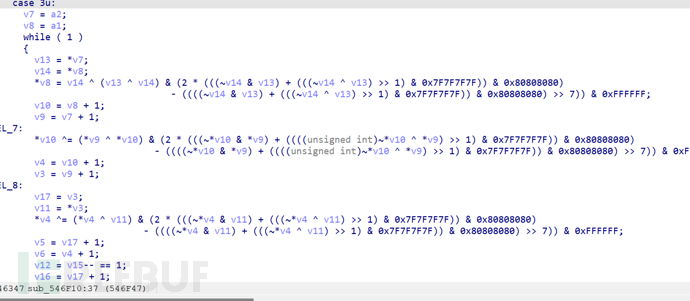
x32dbg下条件断点来看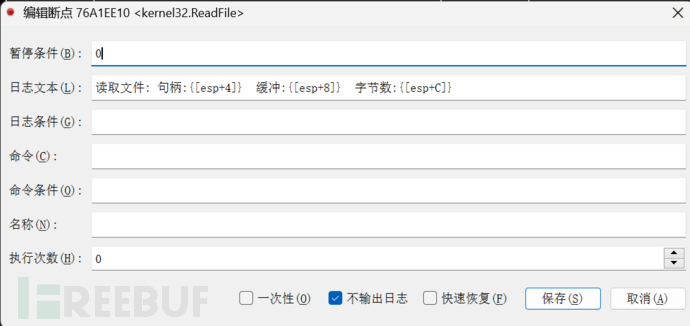
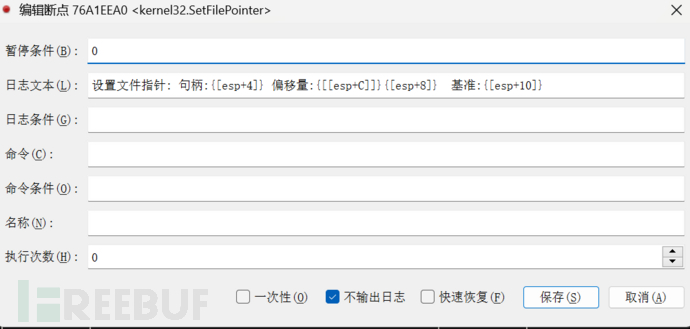
在CreateFileW断到data.xp3时停下 返回用户领空
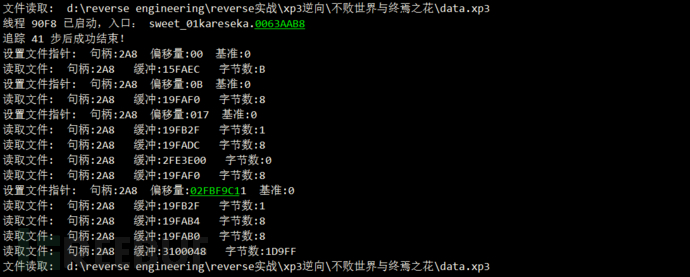
注意到是循环读的 (两次CreateFileW之间就可能有解密?)
文件读取: d:reverse engineeringreverse实战xp3逆向不败世界与终焉之花data.xp3
线程 90F8 已启动,入口: sweet_01kareseka.0063AAB8
追踪 41 步后成功结束!
设置文件指针: 句柄:2A8 偏移量:00 基准:0
读取文件: 句柄:2A8 缓冲:15FAEC 字节数:B
设置文件指针: 句柄:2A8 偏移量:0B 基准:0
读取文件: 句柄:2A8 缓冲:19FAF0 字节数:8
设置文件指针: 句柄:2A8 偏移量:017 基准:0
读取文件: 句柄:2A8 缓冲:19FB2F 字节数:1
读取文件: 句柄:2A8 缓冲:19FADC 字节数:8
读取文件: 句柄:2A8 缓冲:2FE3E00 字节数:0
读取文件: 句柄:2A8 缓冲:19FAF0 字节数:8
设置文件指针: 句柄:2A8 偏移量:02FBF9C11 基准:0
读取文件: 句柄:2A8 缓冲:19FB2F 字节数:1
读取文件: 句柄:2A8 缓冲:19FAB4 字节数:8
读取文件: 句柄:2A8 缓冲:19FAB0 字节数:8
读取文件: 句柄:2A8 缓冲:3100048 字节数:1D9FF
文件读取: d:reverse engineeringreverse实战xp3逆向不败世界与终焉之花data.xp3
设置文件指针: 句柄:2A8 偏移量:00 基准:0
读取文件: 句柄:2A8 缓冲:19F5F8 字节数:B
设置文件指针: 句柄:2A8 偏移量:0B 基准:0
读取文件: 句柄:2A8 缓冲:19F614 字节数:8
设置文件指针: 句柄:2A8 偏移量:017 基准:0
读取文件: 句柄:2A8 缓冲:19F6EB 字节数:1
读取文件: 句柄:2A8 缓冲:19F614 字节数:8
读取文件: 句柄:2A8 缓冲:A00200 字节数:0
读取文件: 句柄:2A8 缓冲:19F614 字节数:8
设置文件指针: 句柄:2A8 偏移量:02FBF9C11 基准:0
读取文件: 句柄:2A8 缓冲:19F6EB 字节数:1
读取文件: 句柄:2A8 缓冲:19F614 字节数:8
读取文件: 句柄:2A8 缓冲:19F614 字节数:8
读取文件: 句柄:2A8 缓冲:326A0A0 字节数:1D9FF
这两次竟然读取同样的数据???
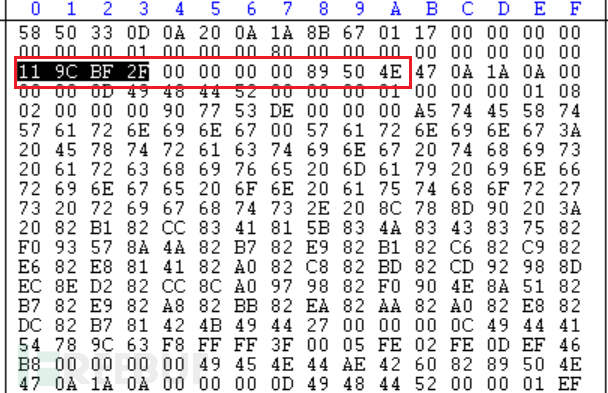
注意到特征都类似 找对应内存看值
对应读取的
第一次 B: 58 50 33 0D 0A 20 0A 1A 8B 67 01 17
第二次 8: 00 00 00 00 00 00 00 01
把另外两个的条件断点都设置中断 对比内存分析
发现并不一样 文件指针是跟着移动了的
第二次读取的B
找到发生变化的分界点 IDA看看找到这里
int __fastcall sub_4DBB30(_BYTE *a1, int a2) { int result; // eax int v3; // esi char v4; // bl int v5; // eax result = dword_7B8CA0; v3 = 0; if ( a2 > 0 ) { v4 = byte_7B8CA4; do { v4 ^= a1[v3]; v5 = result + 1; byte_7B8CA7[v5] ^= v4; result = v5 & 0xFFF; ++v3; dword_7B8CA0 = result; } while ( v3 < a2 ); byte_7B8CA4 = v4; } dword_7B8CA0 = ((_WORD)result + (*a1 & 1)) & 0xFFF; return result; } 发现跟前面的.tpm的算法十分类似 调试发现这里就是一个解密点
注意到传参时sub_4DBB30(&a3, 4);
所以这是部分加解密 而不是整体都加解密的
总结
XP3引擎整体封包流程: 先加密再压缩
加密算法: 官方模板是利用(校验和)末字节逐比特异或 各厂商可以自行修改xor的key值
压缩算法: 与bandizip的gz deflate 3档位以及zlib库的level=9相当
XP3索引部分结构:
对应GARbro源码解析: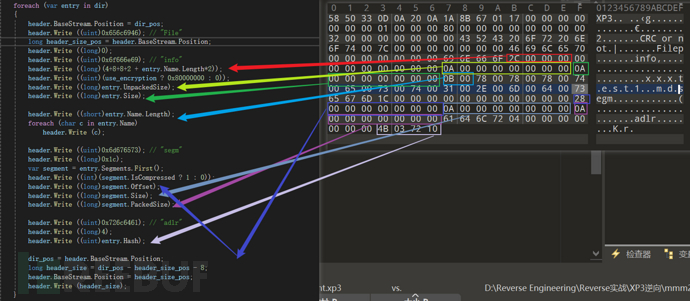
逆向解包流程: XP3头找index偏移 -> 对应各个结构 -> 提取data部分 -> zlib解压缩 -> 厂商加密算法逆向解密 -> 原数据文件
至此 XP3引擎逆向结束
参考文章
http://keepcreating.g2.xrea.com/DojinDOC/HowToCode.html
https://github.com/krkrz/krkr2/blob/master/kirikiri2/branches/2.32stable/kirikiri2/src/plugins/win32/