神经网络水印近年来得到了广泛关注,其中针对分类模型的水印研究最为普遍。对于深度分类模型,嵌入水印的技术途径主要分为(1)嵌入模型参数和(2)植入后门。前者直接将模型参数作为水印载体,而后者通过特殊映射关系建立水印(间接改变模型参数)。本文介绍的2篇论文主要关注深度分类模型后门水印现有研究中较少关注的水印模糊性和保真度两个指标,提出了一些观点和方法,以求提升对应性能和实用性。
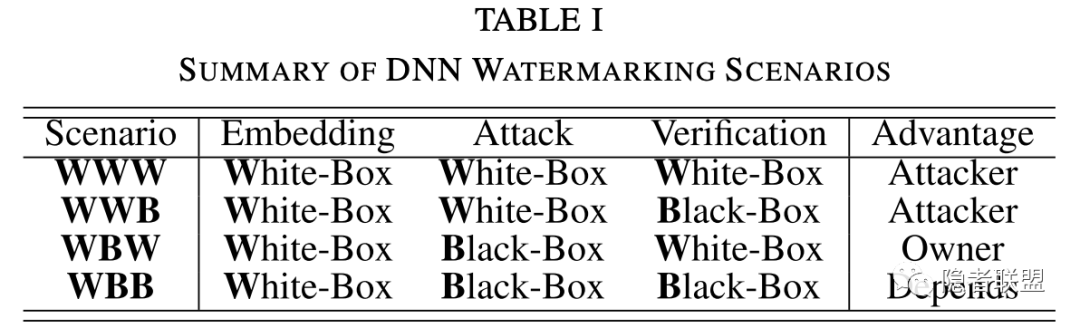
表1 神经网络水印“黑白盒”条件总结
观点1:神经网络水印的“黑白盒”问题
现有研究对神经网络水印中“黑白盒”的定义有所不同,有的关注嵌入过程,有的关注验证过程。本文试图提出兼顾水印嵌入、攻击以及验证过程的全方位视角,如表1所示。值得注意的是,如果攻击阶段为白盒条件,那么严格意义下我们无法对模型进行保护,且问题转为攻击者如何更高效的进行各种攻击。因此,本文主要考虑WBB场景。
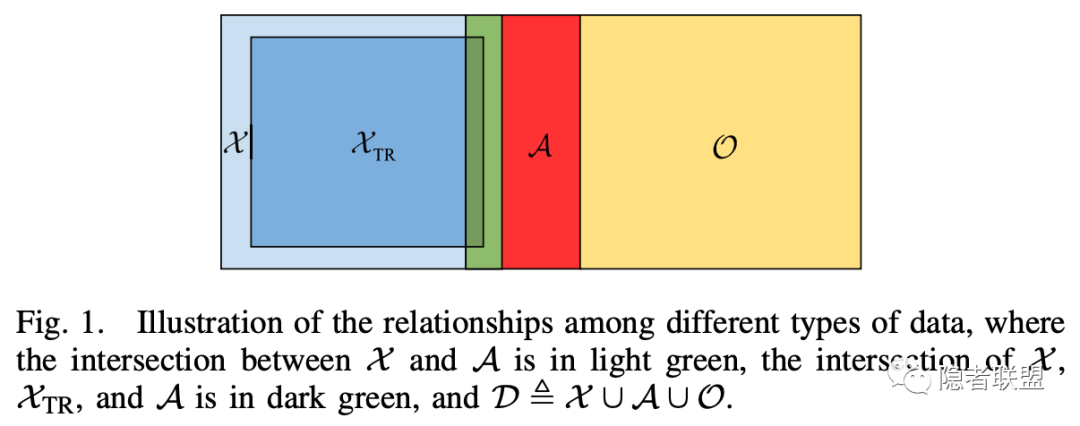
图1 攻击者可选的样本集关系
观点2:后门水印密钥的模糊性问题
现有后门水印研究用一组固定的触发样本和其对应的标签组成水印密钥,在验证时通过比对触发样本的推断结果和密钥中记录的标签实现验证。该协议的风险是攻击者可能通过观测黑盒模型的输入输出,利用丰富的可选样本产生模糊密钥,同样能实现验证。攻击者可选的模糊触发样本如图1所示,包括蓝色的原始域、红色的对抗样本以及黄色的开集样本。因此,如何保证后门密钥的非模糊性(唯一性)是亟待研究的问题。
观点3:神经网络水印的保真度问题
现有神经网络水印的保真度指标(对于最常见的分类模型)主要通过嵌入水印前后模型在原始训练集上的准确率差异进行定量分析,忽略了神经网络这种特殊水印载体内在的特性。图2显示了ResNet18通过重训练嵌入后门水印前后MNIST训练集的特征分布情况,虽然嵌入水印前后准确率几乎不变,但前后模型提取特征的内在机理已截然不同,其在实际部署中面对对抗样本和开集样本时的反应也会截然不同。因此,我们提出深度保真度概念,即嵌入水印前后,模型的内在机理也应尽量保持不变。该概念适用于任意类型的模型和水印。
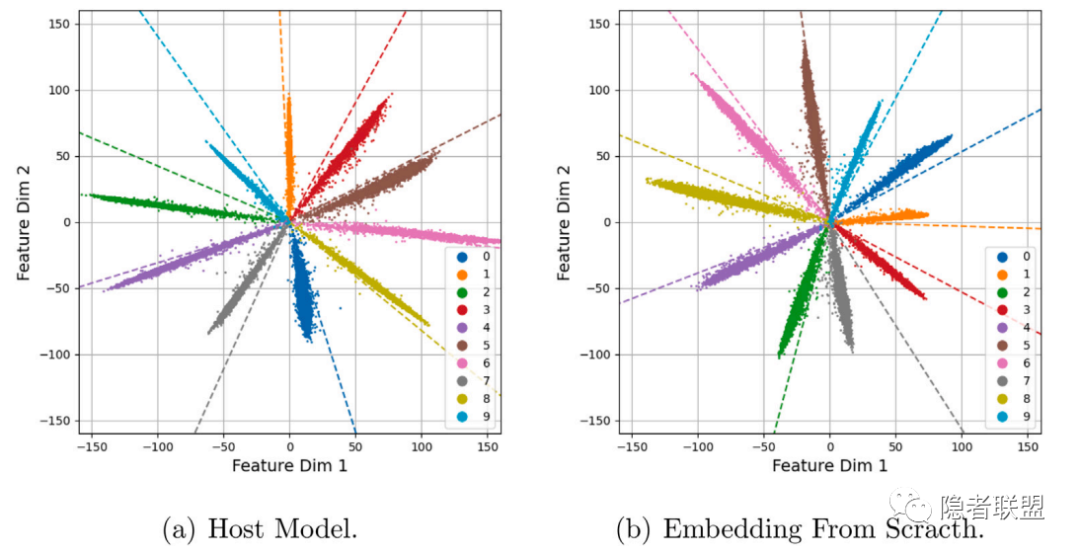
图2 MNIST训练集在from scratch后门嵌入后前的特征分布
方法1:去模糊性的后门水印设计

受R. Zhu et al., “Secure neural network watermarking protocol against forging attack,” EURASIP J. Image Video Process., 2020启发,本文提出利用确定性的映射函数(h和g)分别构建确定相关的触发样本和对应确定相关的标签,形成确定的密钥链(此时Zhu的方法等价于一种基于单向哈希函数的单密钥链方法), 使得攻击者通过观测模型输出构建模糊密钥的成功率大幅下降。
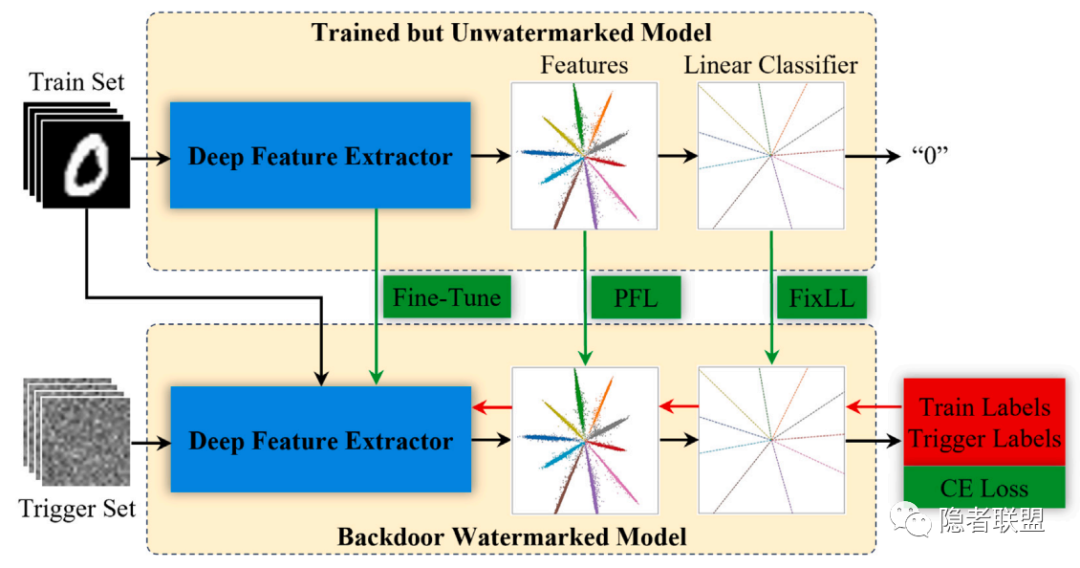
图3 通过监督微调实现深度保真后门水印的嵌入流程
方法2:深度保真度及实现方法

对于分类模型,深度保真度可解释为水印的嵌入应尽量保证模型在原始训练集得到的特征分布和分类边界不变。同时,考虑到数据和算力成本,高质量的大模型往往难以重新训练。因此,我们提出通过微调的方式嵌入后门水印,通过所提附加约束(PFL和SPL)以及固定最后一层线性分类器,实现深度保真的后门水印嵌入。值得注意的是,PFL和SPL可兼容针对分类模型的任意水印方法。
以下问题值得后续进一步研究:
后门密钥可否唯一的设计。虽然本文所提去模糊的密钥链能使暴力搜索的成功率呈指数降低,但并不能证明模糊密钥不存在。因此,唯一性密钥的存在性可否证明,且如果能证明,如何设计,都是具有挑战性的问题。
微调嵌入的鲁棒性问题。现有文献已发现微调嵌入的后门水印相较于重训练嵌入的水印鲁棒性不足,但重训练对数据和算力的要求很高。如何提升微调嵌入的鲁棒性是值得研究的问题。
针对image-to-image或其他生成模型的深度保真水印设计,也是值得研究的问题。
论文信息
相关论文发表于IEEE TNNLS 和 Pattern Recognition,作者为Singapore Institute of Technology 的华光,韩国延世大学的 Andrew Teoh 等。
[1] G. Hua, A. B. J. Teoh, Y. Xiang, and H. Jiang, “Unambiguous and high-fidelity backdoor watermarking for deep neural networks,” IEEE Transactions on Neural Networks and Learning Systems, 10.1109/TNNLS.2023.3250210, 2023.
[2] G. Hua and A. B. J. Teoh, “Deep fidelity in DNN watermarking: A study of backdoor watermarking for classification models,” Pattern Recognition, vol. 144, pp. 109844, Dec. 2023.
论文代码:https://github.com/ghua-ac/DNN_Watermark
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。