
关于leakScraper
leakScraper是一款功能强大的凭证提取工具,该工具由三个子工具组件组成,可以帮助广大研究人员以可视化的形式处理大量文本文件中包含的凭证信息。
该工具专门针对渗透测试人员和红队研究人员设计,主要用于公开资源情报OSINT收集、凭证收集或凭证填充攻击测试等任务。
工具组成
当前版本的leakScraper由三个部分组成:
1、leakStandardizer
该组件可以对你从互联网上获取到的泄漏数据进行标准化处理,它接收一个输入文件,其中可以包含某些奇怪格式的凭证,比如说非ASCII字符或空行,或包含有效邮件地址却缺少密码等数据。通过使用正则表达式,该组件可以使用email:hash:plain(plain为明文密码)这样的格式来生成一个标准化文件。
2、leakImporter
该组件可以将标准化文件导入到MongoDB数据库中,它负责从文件中提取数据,并将其转换为一个兼容MySQL的格式,并创建和管理索引。
3、leakScraper
该组件负责从数据库中挖掘数据,并以用户友好的形式将数据显示到界面上。
工具要求
Linux(Debian)
Python 3.x
MongoDB服务器
工具安装
首先,我们要在本地设备上安装并配置好Python 3.x环境和一台能够有效工作的MongoDB服务器。
接下来,广大研究人员可以使用下列命令将该项目源码克隆至本地:
git clone -b mongodb https://github.com/Acceis/leakScraper
然后切换到项目目录中,执行工具安装脚本即可:
cd leakScraper sudo ./install.sh
上述命令将会安装一些工具所需的Python/Debian依赖包,其中包括python-magic、python3-pymongo和bottle。
工具使用
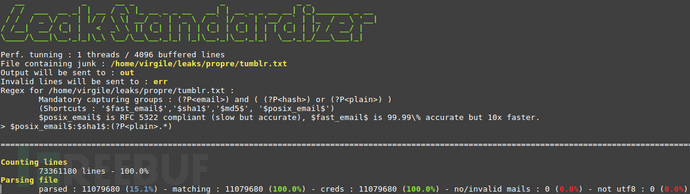
leakStandardizer使用
python3 leakStandardizer.py <leakFile> <cleanOutput> <errorOutput>
上述命令将会提取匹配的凭证数据,并存储到cleanOutput文件中。
在使用leakStandardizer时,我们需要提供一个正则表达式来执行凭证匹配,参考样例如下:
(?P<email>.+?):(?P<hash>.+?):(?P<plain>.*)
leakImporter使用
python3 leakImporter.py <leakName> <leakFile>
python3 leakImporter.py Tumblr tumblr.txt
你需要准备好充足的磁盘空间来存储你的泄漏文件,因为leakImporter会在/tmp目录中创建泄漏数据的副本。
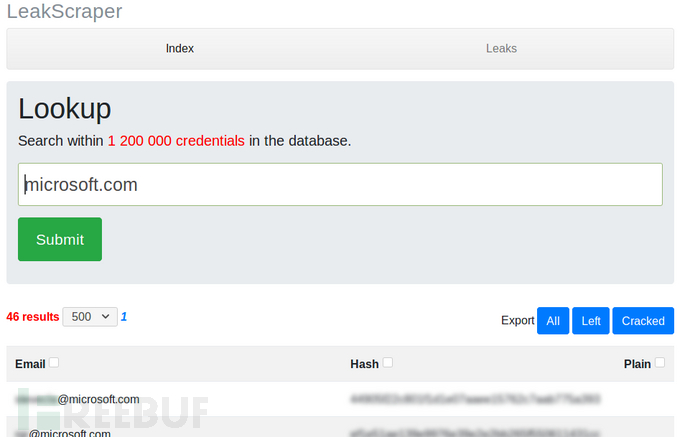
leakScraper使用
python3 leakScraper.py
运行上述命令后,打开浏览器并访问localhost:8080,输入你感兴趣组织的对应域名即可。
工具使用演示

许可证协议
本项目的开发与发布遵循GPL-3.0开源许可证协议。
项目地址
leakScraper:【GitHub传送门】
本文作者:, 转载请注明来自FreeBuf.COM